August 28, 2009

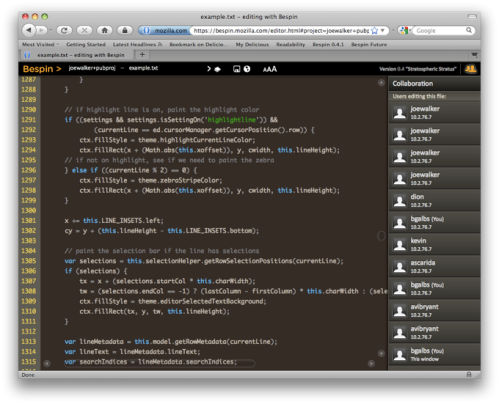
Today we shipped the next release of Bespin: the 0.4.2 “H. E. Pennypacker” release. As discussed in my recent “Bespin Roadmap” blog post, H. E. Pennypacker is primarily a bug fix release focused specifically on issues related to the new collaboration engine. The key fixes in this release include:
- Work towards ensuring that we never lose your data (bugs 511289, 511217, and 511291)
- You can now export projects from Bespin (bug 511828)
- Various other stability enhancements (bugs 511125, 512044, 511539, 509496, among others)
We’re now focused on shipping Bespin 0.4.3 “Chuck Finley” which will deliver deployment and SVN/HG commands (right now we have our own VCS commands that map into SVN and HG; we are working on implementing the actual SVN/HG commands you’re used to).
Command-line Only?
In the bespin mailing list, I saw a message or two lamenting that we are too focused on the command-line at the expense of the UI. Take heart, gentle fans. We have plans to implement GUI equivalents for nearly every major command we can think of; it’ll take us a while to get there.
We hope you enjoy H. E. Pennypacker, and I look forward to telling you more about Chuck Finley in a week and a half or so.






August 28, 2009 12:56 AM
August 27, 2009
I have been working on adding a mouse capturing API, mostly compatible with the IE API. This means that when the mouse button is pressed on an element, you can trap the mouse movement and redirect the movement events to this element instead. This mechanism appears in Mozilla in a number of places already, although there is currently no public way of doing this. For example, try clicking on a scrollbar thumb and dragging it. Notice how when the pointer is moved away from the scrollbar, it continues to move or traps all mouse movement such that other parts of the UI do not respond. When the mouse is released, everything reverts back to normal again. This is used in few other places as well, for example the draggable splitters between columns in a tree view, the splitters between frames and when drag-selecting.
In bug 503943, I am implementing this feature for both XUL applications and web pages.
Using the feature is quite easy:
onmousedown="this.setCapture(false)"
Within a mousedown event handler, just call the setCapture method. This enables capturing on the element until it is either stopped by calling the releaseCapture method, by releasing the mouse button, or if a drag begins. To prevent odd or possibly nasty things from happening, setCapture will only work while processing a mousedown event.
The argument to setCapture specifies whether children of the capturing element will receive mouse events or not. If false, then they do. If true, then only the capturing element receives them. In the former case, you could set capturing on a containing box, yet still handle the mouse as normal inside it.
There are three small incompatibilities with the IE implementation. First, IE allows setCapture to be called at any time and not just when a mouse button is pressed down. This isn’t recommended and usually causes the mouse to go into a funky state where it doesn’t seem to work properly. Naturally, it’s also very easy to abuse this. So Mozilla won’t allow this and instead only allows capturing during a mouse down.
The second difference is that the argument is optional in both IE and Mozilla, but defaults to false in Mozilla, but true in IE. (We’d have to implement some idl changes to change this). It isn’t too much of a burden since you can always supply the argument if this is a problem.
The third difference is that IE has a different event model so compatibility can be affected and can impact what elements seem to receive events.
However, these differences should be minor for normal usage.






August 27, 2009 11:49 PM

Ben, myself, and the Bespin team are obviously excited about what we are doing. Giving Web developers a tool platform that is self-hackable and is also built-in-social has us up at night dreaming. We need help though! One way of course is joining the community, but if you fancy hacking on this problem full time, we have a new job opening for a Mozilla Labs engineer.
If you have a passion for open source, working with community, at an open company and want to spend some time making the editor sexy, please apply.
If you are interested in other positions, Mozilla is hiring across the board. I can tell you from experience that it is very difference working for a mission based organization, and if you think you would like that, come check us out.
August 27, 2009 11:47 PM
With the release of the 0.6 client today, we’re also publishing the 0.5 Weave server release. This release is required to support the 0.6 client if you are running your own server – it uses the brand new API.
If you have a 0.3 installation up, there are migration instructions, or full setup instructions.
The server is designed to run 0.3 and 0.5 side by side (the table is backwards compatible), so you don’t have to migrate all your accounts over at once. However, you should upgrade your clients as soon as possible, because the new client is much better.
Have fun, and hop onto the #labs channel on irc.mozilla.org if you need setup help.






August 27, 2009 10:03 PM
We will have a scheduled maintenance window tonight from 6:00pm to 11:00pm PDT. The following changes will take place:
- 9:00pm PDT (0400 UTC) addons.mozilla.org update. We’ll be updating
addons.mozilla.org to pick up code updates (bug 512892). Duration 30 minutes.
- 9:00pm PDT (0400 UTC) GeoDNS update. We’ll be updating pushing out code updates to our GeoDNS platform. These changes came from Jia Jun from the Google Summer of Code project he worked on. Duration 30 minutes.
Please let me know if you have any reason why we should not proceed with this planned maintenance. As always, we aim to keep downtime to as little as possible, but unexpected complications can arise causing longer downtime periods than expected. All systems should be operational by the end of the maintenance window.
Feel free to comment directly if you see issues past the planned downtime.
August 27, 2009 09:49 PM
The Mozilla Project has a history of producing useful software and tools in the pursuit of its main mission that are not directly in the path of its mission.
MozillaBuild is one of these.
If you're trying to build something that's in any way similar to or remotely expects a Unix-ishy environment, and you don't want to deal with Cygwin's eccentricities1, MozillaBuild not only provides such an environment, but packages a host of useful goodies along with it.
In short, MozillaBuild provides enough "It Just Works (tm)"-ed-ness for the whole family! It's gotten to the point where I often forget that I actually still am in Windows when using it2.
Recently, though, a jarring reminder that I was, indeed, still in Win32-land occurred as I went to install some Perl3 modules a particular tool we use pretty heavily here at Songbird depended on.
I went to run the command on our Win32 release build machine, and was met with a missing-modules error. "No matter, that's what CPAN's for!" I say. Weeelll... not so fast.
It turns out MozillaBuild's Perl installation didn't get the memo that it's in a Win32 environment, so when you try to run CPAN, you'll get all sorts of errors.
Apparently, I'm not the only one to have had this problem.
Since I really needed to get this tool working on Win324, I did some couples counseling with MozillaBuild5 and CPAN, and came up with a fix:
- Configure CPAN.
- Log in as Administrator
- Run perl -MCPAN -e 'shell'.
- When prompted whether you're "ready for manual configuration," say "no"
- Exit the shell
- In an MSYS terminal, manually edit /usr/lib/perl5/5.6.1/CPAN/Config.pm; change the following variables:
- build_dir: [Anything that doesn't contain a space; I ended up using:] /d/.cpan/build
- cpan_home: /d/.cpan
- ftp: /bin/false
- keep_source_where: /d/.cpan/sources
- urllist: q[http://mirrors1.kernel.org/pub/CPAN], q[http://mirrors2.kernel.org/pub/CPAN], q[http://ftp.osuosl.org/pub/CPAN/]]
- Run perl -c on /usr/lib/perl5/5.6.1/CPAN/Config.pm to make sure it compiles and you didn't typo anything in the changes you
- Apply the following patch to /usr/lib/perl5/5.6.1/CPAN.pm.
And you're done!6
You should now be able to run commands like:
perl -MCPAN -e 'shell'
install Digest::Perl::MD5
force install URI
One (rather large) caveat to this process is many Perl modules have C extensions that get built at installation time. Most of these assume Unix, and therefore that gcc is around.
If you don't have a full MSYS environment, installing them will fail, unless you can turn these bindings off. (Even in the case of some modules (URI, for instance), they will refuse to install because of failed tests; you can get around this by forcing an installation.)
It's not perfect, but if your requirement is pure Perl modules, as mine was, it's a workable solution.7
__________________________
1 And less-than-spectacular performance
2 as much as that's possible to do; I usually remember around the point I want to copy/paste some text around...
3 Yes, yes, I know; Python forever... but every build infrastructure I've ever worked with has perl in it... somewhere
4 Otherwise, our Lord and Savior, AUTOMATION, couldn't proceed
5 I experienced this issue with MozillaBuild 1.3, but I checked the latest MozillaBuild and the Perl installation there doesn't seem to have changed, so this process+patch should still be applicable
6 What this process is generally doing is: removing paths with spaces in them, since %20's in Unix paths are a rarity; skipping manual CPAN configuration which will get tripped up on a bunch of things and generally try to install the world for you; always cause ftp commands (which use ftp.exe) to fail, since ftp.exe != the venerable unix ftp, and the CPAN module will get very confused trying to talk to it; and finally, forcing CPAN to always use wget, which MozillaBuild includes, but not use redirection to save files, since MSYS seems to (unhelpfully, I might add) attempt to translate line endings for you.
7 Until you just rewrite your can't-live-without-it tool in Python...
August 27, 2009 09:33 PM
David joins Mozilla full-time after a stint as an intern from Worcester Polytechnic Institute and then some contracting. His work focuses mainly on TraceMonkey and its Nanojit component. He blogs at http://www.bailopan.net/blog/.
Please join me in welcoming David!
August 27, 2009 09:06 PM
Weave Sync is a prototype that encrypts and securely synchronizes the Firefox experience across multiple browsers, so that your desktop, laptop and mobile phone can all work together. It is part of the Weave project, which aims to integrate services more closely with the browser.
Major Features
What is Weave Sync all about? In short, Weave Sync lets you securely take your Firefox experience with you to all your Firefox browsers — including our mobile browser, codenamed Fennec. It currently supports continuous synchronization of your bookmarks, browsing history, saved passwords and tabs, as well as form-field history and preferences. For example:
- Get the same results on the Smart Location Bar on each of your Firefox browsers, so you can get to your favorite sites with just a few keystrokes
- Continue what you were doing: have the ability to open any tab you have open on any of your Firefox browsers
- Keep the same list of bookmarks on all of your Firefox browsers
- If you use Personas, your currently selected Persona can be synchronized across your Firefox browsers
- Easily sign in to all your favorite sites using your saved passwords (this is especially handy on mobile phones, where it’s hard to type in complex passwords)
- Do it all securely: Weave Sync encrypts user data before uploading it to Mozilla’s servers, so that only you can access your data
What’s new in 0.6?
If you have not looked at Weave recently, now is a great time to jump in and try it out! In this release we did a major overhaul of the user experience, as well as major improvements in terms of reliability and performance. A few of the major changes are:
- Brand-new UI, allowing for most set-up, configuration, and status to be done from a single streamlined interface
- Major performance improvements during upload and download
- Better error handling and reporting
Getting Involved with Testing and Development
– Dan Mills, on behalf of the Weave development team
August 27, 2009 08:35 PM
I’m becoming increasingly obsessed with the whole concept of professional feedback because, done well, it’s the fastest way to learn and grow and advance. A lot of this is sparked by playing around with Rypple and trying to figure out how to make the best use of that system — but the basic idea of soliciting regular, lightweight, specific, and concrete feedback strikes me as a fundamentally solid idea. It’s sort of the personal development version of “release early, release often,” in a way, with a dash of “given enough eyes, all bugs are shallow” thrown in for good measure. Um, to possibly stretch the metaphor.
Anyhow, the problem is that it turns out that asking for and giving feedback can be difficult. Asking a good question is a lot harder than I thought, and giving useful and constructive feedback is complicated by a whole variety of factors. I generally learn by reading, so I’ve started digging around and reading as much as I can about feedback. I figured I’d start linking to the interesting stuff I find, in case other people might find it useful as well.
A bunch of this first batch are from the Rypple weblog, which is a good place to poke around — there’s lots of interesting stuff over there.
August 27, 2009 08:01 PM
If you’re never built an add-on but really want to enter the Extend Firefox 3.5 contest, we have some resources that will help get you up to speed. First we have Robert Nyman’s excellent tutorial on building add-ons:
How to develop a Firefox extension by Robert Nyman
Also, two great videos to help you get started are below:
Extension Development 101
Extension Development 101 from rhian on Vimeo.
Extensions Bootcamp: Zero to “Hello World” in 45 Minutes
Extension Bootcamp (Mozilla Labs Design Challenge: Spring 09) from Mozilla Labs – Concept Series on Vimeo.
And don’t forget that we’ve created an Extend Firefox 3.5 discussion group to answer an questions you have about the contest. Good luck!
ShareThis
August 27, 2009 07:32 PM
Moving files into jars reduces amount of seeks on startup, and has miscellaneous other performance/organization benefits. I added resource://gre-resources/ which maps to jar:toolkit.jar!/res/.
To move a file into a jar:
- Add a jar.mn entry.
- Remove existing references to the file in Makefile.in, packages-static files
- Add file to the removed-files.in list of dead files
- Update urls refering to the file in the source. Sometimes one has to switch from using file streams and filenames to using channels and URIs. This is the hard part.
- Set your bug as blocking bug 513027.
For an example see bug 508421.
August 27, 2009 06:40 PM
Here's a sneak preview of a project I've been working on in my spare
time for a while, and which is nearing its first release:
'Stratified JavaScript' ('SJS') is a cross-browser extension to
JavaScript which adds some concurrency features to the
language. Without going into too much detail, the main features
include:
(1) The ability to pause execution
The function
hold(time_ms);
pauses execution of a piece of code for time_ms milliseconds. E.g.:
var elem = document.getElementById("animated_element");
var x = 0;
while (true) {
elem.style.left = x;
x = (x + 10) % 200;
hold(100);
}
(
Run it)
Note that 'hold' doesn't busy wait. The browser's UI stays fully
functionally while this code executes.
(2) Fork-Join Parallelism
In conventional JavaScript, arguments to function calls are evaluated
sequentially. In Stratified JavaScript, they are evaluated concurrently:
function animate(elemname, duration_ms, step_ms) {
var elem = document.getElementById(elemname);
var start_time = new Date();
var x = 0;
do {
elem.style.left = x;
x = (x + 10) % 200;
hold(step_ms);
} while (duration_ms > new Date() - start_time);
}
function par(a, b) {
alert("all done");
}
par(animate("animated_element_1", 10000, 100),
animate("animated_element_2", 7000, 80));
(
Run it)
Here, the two 'animate' calls are being executed concurrently. Once they
both return, the body of 'par' gets called.
(3) Exploratory parallelism
Many concurrency problems fit into the pattern
"Explore options a,b,c,... concurrently. Once one of them yields a satisfactory
result, return it and abort exploration of the remaining options."
Exploratory parallelism in Stratified JavaScript is embodied by the
'@' ('alt', 'alternatives') operator:
animate("animated_element_1", 10000, 100) @
animate("animated_element_2", 7000, 80);
alert("all done");
(
Run it)
This code pops up 'all done' after 7s (after the animation of
animated_element_2 has finished). At the same time, the animation of
animated_element_1 will be aborted.
In many ways, exploratory parallelism forms the heart of Stratified
JavaScript. It is applicable to many situations which are very
cumbersome to express in conventional thread-based parallelism.
(4) Suspend/Resume
Most JavaScript programs live by asynchronous events, e.g. events
generated by button clicks, or asynchronous
XMLHttpRequests. Stratified JavaScript contains a generic mechanism
for converting these asynchronous constructs into synchronous ones:
suspend {
... resume() ...
}
retract {
...
}
finally {
...
}
This will be executed by first evaluating the code in the 'suspend'
block and then suspending execution. Execution will resume when the
'resume' function defined in the suspend block is called. The optional
'retract' block will be executed if the current code is aborted before
'resume' was called. The optional 'finally' block will be executed in
either case; if execution was resumed, or if execution was aborted.
E.g., this is how an event listener could be 'synchronized':
function waitForEvent(event, elem) {
suspend {
var rv;
var listener_func = function(e) {
rv = e;
resume();
};
elem.addEventListener(event, listener_func, false);
}
finally {
elem.removeEventListener(event, listener_func, false);
}
return rv;
}
With this function we can now e.g. wait for a button click:
while (true) {
waitForEvent("click", document.getElementById('button1'));
alert("You clicked the button");
}
(
Run it)
Or something more complicated:
function dump(message) {
document.getElementById("output").innerHTML = message;
}
while (true) {
var e = waitForEvent("click", document.getElementById('button1')) @
waitForEvent("click", document.getElementById('button2')) @
hold(5000);
if (e)
dump("You clicked button '"+e.target.id+"'");
else
dump("Click a button already!");
}
(
Run it)
If all of this sounds similar to Oni, that's because it is. Under the hood, Stratified JavaScript is executed by a runtime based on Oni.
Everything that can be expressed in Stratified JavaScript can be written directly in Oni without going through any compilation stage. The advantage of Stratified JavaScript is that
it doesn't have the awkward functional syntax of Oni.
August 27, 2009 06:25 PM

I’m sure you’ve all heard (just a few times) that Facebook and twitter can be a waste of time — but did you know that your hours spent using Social Media can help non-profits? Social Media tools can greatly help an NPO connect with its community, donors and the general public – for free!
As you may know, we’re in the process of rolling out action templates for Mozilla Service Week for those that would like to create their own opportunities or need a little more flexibility They’re sets of actions and resources that you can use to help non-profits, organizations and individuals improve their experience online and allow them to better leverage the Web. This week’s template focuses on Social Media (Digital Marketing Template) and guides volunteers through setting up organizations with a preliminary social media marketing framework (see Chelsea Novak’s blog for more details).
Tara Shahian, Jeff Zeller and I conducted our first Social Media seminar this past Monday at Envision Schools. Not only was it a lot of fun, but it opened their eyes to new ways to use twitter, Facebook, Twibbon and more. A few learnings:
- Clarify upfront their goals and audiences — this will better shape the conversation and set of tools you recommend.
- Not everyone has a built-in Social Media audience like Mozilla & Firefox. We spent some time talking about how to build a base on twitter and Facebook. It really helps to leverage existing communications channels such as newsletters and tapping into friends and supporters to get the word out.
Feel free to use my presentation and let me know if you have any feedback or want to share a “remix.”
We’re hoping these templates make it easier for you to act! If you have any ideas on new ones or would like create some, please comment here. A few ideas to keep in mind if you’d like to use these templates or others:
- Take a moment to pledge your hours.
- Share your plans or stories on Mozilla Service Week’s site — it will help provide inspiration for others.
- Challenge your friends to do this as well using PledgeBank (i.e. I will perform 10 Internet Health Checks if 20 of my friends do so as well).
And, remember to have fun!






August 27, 2009 05:33 PM

We’re getting close to Mozilla Service Week — it’s just 18 days away! We’ve had over 4,300 hours pledged and over 2,200 volunteer opportunities posted. We’re in the process of rolling out action templates for Service Week and OneWebDay for those that would like to create their own opportunities or need a little more flexibility They’re sets of actions and resources that you can use to help non-profits, organizations and individuals improve their experience online and allow them to better leverage the Web. Check them out:
- Internet Health Check: Online privacy and security are major concerns for everyone. The Internet Health Check provides four easy steps to update a computer’s browser and plug-ins. You can perform Internet Health Checks for an organization or friends and family.
- Digital Marketing: The Digital Marketing Template was created to help Service Week volunteers get organizations set up with a preliminary social media marketing framework (see Chelsea Novak’s blog for more details). Social Media tools can greatly help an NPO connect with its community, donors and the general public – for free!
We’re hoping these templates make it easier for you to act! If you have any ideas on new ones or would like create some, please comment here. A few ideas to keep in mind if you’d like to use these templates or others:
- Take a moment to pledge your hours.
- Share your plans or stories on Mozilla Service Week’s site — it will help provide inspiration for others.
- Challenge your friends to do this as well using PledgeBank (i.e. I will perform 10 Internet Health Checks if 20 of my friends do so as well).
And, remember to have fun!
August 27, 2009 04:26 PM
One of my jobs is to be a Data analyst and generate statistics by parsing,scraping
and formatting data and ultimately to generate graphs and self analysis
tools for managers.
I have been working with sanitized Bugzilla database to generate blocker bugs daily in-flow out-flow trend graphs. Bugzilla DB admin has been very kind to provide me with a sanitized Bugzilla dump database which is hosted on a secret server in colo and I can access that db instance in read only mode and that too , by VPN'ing to a specific server in server room. So, naturally I am getting a little bit tired of going through multiple firewalls to access the naked DB instance.
So, today I got an idea. Why not I get the required information all from the BugZilla front end from the master DB itself [ instead of having a sanitized back end DB replication ] !! This will allow me to quickly automate the graphs generation job.
So, here is what I did in about 2 hours ... I wrote a crazy PERL script that gets an ATOM feed from Bugzilla and then grabs the list of all BugIds' that match my query. Then for each bug the Bugzilla is again queried to get an XML output for each bug [ which will contain a ton of information like when the bug was filed, who filed, status, product,component, severity,priority, blocker status etc., etc., ].
However, the XML response back from Bugzilla does not provide the historical activity on the bug. This activity includes every thing that has ever happened to the bug and provides the transient state information on the entire life history of the bug.
I can query the Bugzilla to get the activity info on any bug but Bugzilla returns the info in a plain old HTML table format. The table contains rowspans, colspans etc., to make my life exciting.
So, I wrote another crazy PERL script that queries for each bug [ that fits my criteria ] and gets the activity in HTML table format. Then parses the HTML table to get information like how many times the bug is RESOLVED - Reopened - RESOLVED or when the bug was actually marked as confirmed or when the bug was flagged as a blocker and who did it..... and any such info that I would be interested in.
I pumped all this data into a simple sqlite3 database which is created on the fly and this way, I can port my entire scripts set to any machine that has PERL and has the right PERL modules.
Using the seed information I grabbed from the Bugzilla database, I was able to create some nice graphs that show the IO trends of blocker bugs in more than one view and also on more than one time scale.
Look at the graphs generated here LINK.Just like my previous graphs
here,
here and
here the above graphs set would also be generated using a cron job on a daily basis.
Your reviews and comments are always appreciated.
August 27, 2009 02:39 AM
I spent the day looking into
- Issue 2187: firebug causes memory leaks
I still don’t know if there is a memory leak (or even how to find it if there is), but I sure found a problem. When Firebug’s Error module is active and we load gmail.com, it takes about 90 sec on Firefox 3.7 nightly build. With the Error module inactive, it’s about 6 seconds. (On a Firefox debug build the load never completes). The memory goes up dramatically, so my guess it that this is the source of both the excessive CPU time and apparent leaks. Note that gmail.com does generate a huge number of errors.
For now the only workaround is to disable the Firebug Console (with the mini menu on the Console tab). Firebug 1.5a22 will have a slightly better workaround, it will disable the Error module if you turn off all error and warning settings in the Console.
To find the problem itself may be hard. Chromebug’s profiler did not work, so I’ll fix it and see if that gives some hints. There is not a lot of code in Firebug’s Error module, so I’m surprised that is the culprit.
jjb
Follow up on the newsgroup please.
August 27, 2009 12:55 AM
August 26, 2009
We’ve just released Camino 1.6.9, a maintenance release which contains various security and stability updates to Camino 1.6.x. All users are urged to update.
In addition, Camino 1.6.9 is available in the following languages:
- Catalan
- Chinese (Simplified)
- Czech
- Dutch
- English (US)
- French
- German
- Italian
- Japanese
- Norwegian (Bokmål)
- Polish
- Portuguese (Brazillian)
- Russian
- Slovenian
- Spanish (Castellano)
- Swedish
Download Camino 1.6.9 in English or its multilingual version now.
August 26, 2009 10:00 PM
Most of my posts are related to getting the unittests to run on Fennec, there is not much communication about how we are tracking and getting the tests to be green (zero failures). Simple explanation, up until now there was no plan.
Last December, I went through every failure and documented what I thought was the problem. I created a little web tool to see the differences and track my bugs. Of course this is a static tool and was a real pain to update with new bugs and tests.
Now it is August and many new failures are occuring and the old failures are not fixed. I am going to outline an approach to get us to ZERO failures by the end of the year. In order to be successful, we need to reduce the variables as much as possible. This means that we will run Fennec on desktop linux builds in tinderbox per checkin instead of on Maemo! This sets us up for getting green Tinderboxes in this environment vs a device (I suspect we will be 90%+ passing when run on a device).
Actions to take:
- Start with XPCShell tests first (then do Crashtest, Reftest, Mochitest, Chrome one at a time) and for each failure do the next steps
- Reproduce failure (twice)
- Reduce testcase (if possible)
- File bug/update existing bug, add bug # to a master tracking bug
- When done with a specific test harness (XPCShell in this case), meet with the devs to prioritize bugs and get everybody on the same page
This sounds simple but could take a long time. The benefit of tackling the smaller test harnesses first is that we can see progress (list of bugs, green) faster and start keeping those harnesses green.
What this does not do:
- Help us track new failures
- Get green tinderboxes on Maemo and WinMo
- Resolve remote web server related issues
- Fix issues when running tests one at a time
Stay tuned for an update when we get our first batch of bugs filed for XPCShell.






August 26, 2009 09:36 PM
Asa passed me this Read Write Web article about the Worldwide Lexicon’s project, Firefox Universal Translator, which helps translate web pages automatically within the browsing experience. The tool enables project members to create, curate, and share translations. Have you seen it and what do you think? I’m curious to hear.
ShareThis
August 26, 2009 08:44 PM

Photo by (le)doo.
Last week’s meetup in New York City was a great event bringing together developers to learn about add-on development and hear about the newest features on AMO.
We’ll be hosting another meetup in Miami, FL on September 15th so if you’re in the South Florida area, this will be a great opportunity to get to familiar with add-on development and have an opportunity to share your ideas with the AMO team.
The full details of the event are up on the Mozilla wiki:
Mozilla Add-ons Meetup: Miami, FL – Sept. 15th 6-9PM EST
There’s no cost for the meetup and it will be packed with great sessions. Look forward to seeing you there!
ShareThis
August 26, 2009 07:43 PM
Our sysadmin team will be taking time this Friday to upgrade our production machine's OS to the latest version in order to continue providing the security and stability that Mozdev users have come to expect.
We expect the downtime to be approximately 1-3 hours starting at 07:00 UTC on Friday the 28th but are scheduling a 6 hour window to be safe.
If you have any questions about the downtime and how it will affect your project, feel free to get in touch with us.
August 26, 2009 03:41 PM
I’ve posted two new items as a part of my Drumbeat notes series — a simple slide deck and a public wiki. They provide an overview and invite feedback on the Drumbeat concept. Here are the slides:
A huge shout out to all the people who are already helping to shape Drumbeat. As I’ve been documenting in all my notes, you’ve played a critical role in clarifying where we want to go.
Next step: digging into the framework in the slides above, strawmanning specific event and campaign ideas.
PS. I’ve you’re new to the Drumbeat concept and want some setup, a good place to start is my I heart the open web talk from OSCON.
Posted in drumbeat, mozilla






August 26, 2009 02:35 PM
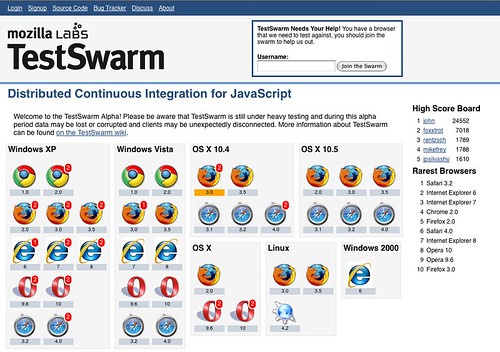
TestSwarm, the project that I've been working on over the past 6 months, or so, is now open to the public. Mozilla has been very gracious, allowing me to work on this project exclusively. At the beginning of April I moved from my old position as a JavaScript Evangelist on the Mozilla Evangelism team to that of a JavaScript Tool Developer on the new Developer Tools team (whose other major project is Bespin).
For more information on Test Swarm I've written up a detailed explanation of what Test Swarm provides and where it fits into the landscape of JavaScript developer tools.
I've also recorded a screencast walkthrough of the TestSwarm site:
Test Swarm Walkthrough from John Resig on Vimeo.
Additionally, there are two previous posts that I've made on TestSwarm:
There are some additional screenshots of Test Swarm in action on Flickr.
More Information:
If you're interested in using Test Swarm I strongly recommend reading the project overview first. If you have any further questions please direct them towards the Test Swarm discussion Group.
TestSwarm ended up being a very challenging project to get to an alpha state (and probably will be even more challenging to get to a final release state). Dealing with cross-browser incompatibilities, cross-domain test suite execution, and asynchronous, distributed, client execution has been more than enough to make for a surprisingly difficult project. It's mostly written in PHP and uses MySQL as a back end (allowing it to run in virtually any environment). Patches will absolutely be appreciated.
This project has been a long time coming now, the first inklings started back in 2007. Some of us on the jQuery team were discussing ways to distribute the test suite load to multiple browsers in an automated fashion. Andy Kent came along and proposed a participatory application for testing visual code (such as jQuery UI). We worked on that code base for a while but it didn't get off the ground. Eventually I decided to re-tackle the problem early on in 2009. Even in its rough alpha state we've already been able to make great use of TestSwarm. For example, here's a view of jQuery commits run in TestSwarm:
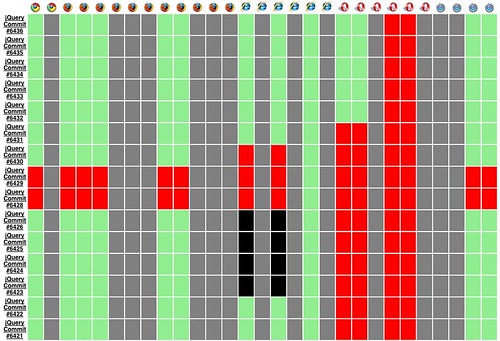
The vertical axis is SVN commits to jQuery (newer commits at the top), the horizontal axis are all the different browsers that we target. Using TestSwarm we've been able to easily spot regressions and fix them with a minimum amount of hassle (especially since all the results are logged).
And this is only the beginning. There are so many different directions in which Test Swarm can be taken. For example:
- A pastebin-like service where you can drop in code and see the results come back, from many browsers, in real-time.
- IDE integration for sending minor changes out for quick testing.
- Manual testing of user interface code. Pushing manual tests, with instructions, to users for them to walk through.
- Distributing tests to any number of browsers, rather than a specific sub-set. (You could use this to embed a tiny iframe in your site to collect test results from a small sampling of our users.)
- The ability to drive and test browser code or extensions.
And the list goes on. I'm definitely curious to see what directions the community is interested in driving the code base. I've gotten it to a level where it's particularly useful for me and the jQuery team - where should we go from here?

August 26, 2009 09:44 AM
For those of us in the business of making technology for the People of the Internet, it’s easy to get jaded by the mainstreaming of technology which we once found new and exciting. Americans in particular seem to be a little guilty of this, particularly if they live near a coast. While Twitter, Facebook and Firefox move further into the homes of our friends and parents, it’s good to see this as an opportunity and not a sign that the end has come.
I’ve had the good fortune of meeting fellow nerds from all over the world, and I’ve noticed the ones who don’t come from Silicon Valley remain enchanted by technology and its promise to make the world better. They’re the ones hacking away on Twitter and Firefox and really pushing the envelope on the future for those products. Many of top Firefox add-on developers come from Europe and Asia, and Brazil’s wholesale adoption of open source and social software is a phenomenon to behold. Korea’s obsession with Starcraft shows no signs of waning eleven years after that game’s release.
While our short attention spans compel us to keep creating and trying new things, does our eagerness to invent prevent us from honing our craft? Does great software evolve through people who lose their otaku sense of wonder? Seesmic relocated to San Francisco in an attempt to secure respect in the startup world, but I wonder if Silicon Valley, with its populace of short-attention-span inhabitants, will continue to be the epicenter of technology moving forward.
I’m not terribly worried about America- I still see that twinkle in the eyes of my friends and colleagues from other parts of the country, but I do think that we should get over ourselves and try to remember that technology that makes the lives of people better is something that we want in the hands of as many folks as possible.
August 26, 2009 07:59 AM
The www.mozilla.org site has just been relaunched! And this is just the beginning—there are many more ideas to make the site better.

This is the community’s site and it’s truly been a community effort to create a new look as well as a new vision. Many people were involved with the redesign, but several community members have also been doing a lot of less visible work (modernizing the server, dealing with abandoned content…).
I’d like to thank Sam, fantasai, Reed, Robert, Chris, Stephen, Jeremy, Gordon, Eric, John, Simon, Frank, Mark and everyone at Happy Cog and silverorange for making this happen (and I apologize for anyone I’ve left out).
There’s lots more to do, so if you’d like to get involved with the site let me know.






August 26, 2009 04:50 AM
SeaMonkey:StatusMeetings:2009-08-25
From MozillaWiki
« last meeting | index
SeaMonkey Meeting Details
- Who’s taking minutes? -> Ratty
(who needs to do what that hasn’t been recorded in a bug) We should assign people to the open items.
NEW
OPEN
- Get permission from Google to use their geolocation JSON service [KaiRo]. Contact at Google says: “We don’t have a good estimate for when GLS will be opening up more broadly, but I will be sure to let you know when we take that step. Sorry that I can not be more specific at this time.” – We can only wait right now.
CLOSED
- File bug on target milestone and flags for 2.1a1 [KaiRo]. Filed and already fixed as bug 512086 together with the 1.1.19 flags/keyword.
open blockers (4)
blocker requests (0)
- IanN has started triaging nominations, KaiRo finished them!
- Code freeze: September 1 – string freeze August 27 (both 23:59 Pacific).
- Targeted ship date: September 8 (Firefox 3.0.14/3.5.3 are targeted Sep 9).
- Thunderbird is targeting Beta4 release on 22nd September with 11th September for code freeze.
- We need to care that they keep shared code stable during the timeframe we need, and the strings in suite/ need to be frozen during our string freeze, which includes mailnews strings. The code freeze period for us should be fairly short, if we have no blockers left on Sep 1, we can do builds on Sep 2 and unfreeze immediately. The string freeze is the real impact.
- Tabmail is the big missing feature.
- Should be in final review stages, biggest part is probably IanN’s review.
- The API changes of bug 474701 would be nice to get, Lightning uses some part of it, filed bug 509324 for that.
- This is our last beta, and that means that September 1st is also feature freeze for the 2.0 series! Exceptions will only be granted in rare and really-high-value cases.
- Do we have to look for bugs that may need help making the string freeze?
- If we have more features to land for the 2.0 cycle, we should really get them pushed into the tree now or wait for 2.1, unless they are really high reward and we think we really want them in 2.0.
- Thunderbird can’t guarantee that they can hold string freeze past the 2nd.
- suite/ will accept new strings for a while in September, but we want to keep changes small once we’re officially feature-frozen next Tuesday.
- If we have all blockers resolved by code freeze next Tuesday, we can start the release process with tagging on Wednesday and once the relbranch is tagged, we can unfreeze.
- Current blockers: status?
- bug 474709 Depends on the review, but mcsmurf thinks the patch is good. Note: has string impact.
- bug 507896 Should not be that difficult to fix [mcsmurf].
- bug 505832 The relevant AMO people have been poked [KaiRo].
open blockers (4)
blocker requests (36)
open wanted (18)
wanted requests (31)
- IanN will start triaging blocker and wanted requests.
- We can probably put off a number of things, where they sound useful, to 2.1a1 or 2.1.
- Target schedule: Freeze October 6, ship mid-October?
- Thunderbird is expecting RC1 freeze on 3rd November but string freeze also on October 6 or so.
- Freeze on October 6th should allow at least a week of string freeze for final and allow us for some time of candidate testing, whether we push them as public RC releases or not.
- We can look at more details closer to when 2.0b2 is about to go public.
Bug statistics for last two (full) weeks: 62 new, 26 fixed, 24 triaged.
Major wanted/needed features:
- Toolbar customization aftermath [Ratty]
- bug 481862 We still need small button icons for modern in MailNews. Needs someone who understands both css and svg/graphics.
- bug 509209 Implement Customizable Toolbars in SeaMonkey Message Compose. Has patch. Waiting reviews.
- bug 460960 Port Thunderbird tabbed interface to MailNews.
- It is to be hoped that we can get positive reviews from both IanN and Neil before Thursday so that we can finally land it.
- bug 460699 Make the default theme look better on mac.
- bug 456757 Modern theme update [Ratty].
- bug 493022 Add mozapps/ to the modern theme. landed!.
- Now working on bug 465924 Modern Update: changes in global/. textbox.css, and wizard.css need some minor polish. notification.css needs to be updated but depends on bug 512254 Port bug 429282 (Land new windows icons (20080416)).
- bug 348720 New icon set for “SeaMonkey Default Theme”.
- bug 460953 Port jminta’s kill-rdf to SeaMonkey where applicable.
- sgautherie is working his way steadily through porting all the relevant Thunderbird bugs.
We also should take a careful look at the other items on wanted-seamonkey2+ for things like
things like:
- bug 436794 Enable Mac OS X system address book per default and add UI.
- bug 508039 Port |Bug 456439 - add about:rights and a "Know Your Rights" infobar to Firefox| to SeaMonkey.
If there’s anything on that list you think we shouldn’t take for 2.0 any more, please notify KaiRo, so we can push them to 2.1.
- bug 410613 OpenSearch. helpwanted.
- We need to check if OpenSearch can support all our existing functionality, for example the INTEPRETS section in Sherlock search plugins. Mnyromyr will check on that, and on how extensible the Firefox code is.
Status Updates from developers – what are you working on, what’s the progress, any other comments? (feel free to add yourself to the list if your name is missing and you have interesting status).
- Usual testing, reviewing and commenting.
- Started release process for SeaMonkey 1.1.18, which has a major NSS upgrade. We found one regression in Windows candidates, a packaging miss rendering SSL unusable, patch is about to be checked in and builds regenerated.
- As always, my blog has more detailed status about my work.
- Checked in bug 483980 Allow history/bookmark observer components to register with a startup category which fixes bug 484175 History Import from SeaMonkey 1.1.x is not working
- Fixed bug 495680 Problems with import of downloads.rdf after switch to toolkit download manager
- Got bug 481836 URLbar autocomplete fills in nonexistant URL going again
- Created patch for bug 474709 Subscribing to a feed (triggered by an external application) while no RSS account is present, does nothing
- Started to port sessionstore bugs again, there is a lot them yet unported. Now working on:
- bug 511635 Port Bug 455070 [Make sessionStorage object conform the WHATWG spec] to SeaMonkey.
- bug 510890 Port Bug 394759 (Add undo close window feature) to SeaMonkey.
- bug 511640 Port Bug 490040 [Reattaching a lone tab into another window causes an empty window to be added to Recently Closed Windows].
- bug 511823 Port Bug 494543 [Can't add items to Dell.com shopping cart] to SeaMonkey.
- Bugs Fixed:
- bug 509367 Race condition during parallel build.
- bug 510786 addrbook.gif needs some transparency.
- bug 511797 [SeaMonkey] mozilla-central builds do not compile after bug 380917 landing.
- Bugs Fixed:
- bug 507871 “New Msg” button: Highlight default action in the pull down menu.
- bug 493022 Add mozapps/ to the modern theme.
- Working on:
- bug 465924 Modern Update: changes in global/.
- bug 509209 Implement Customizable Toolbars in SeaMonkey Message Compose.
- bug 511096 Port FUEL Bug 458688 (test browser_Browser.js still times out occasionally).
- Bug triage and bug discussions.
- AgitProp and PR in http://forums.mozillazine.org/
- bug 460953 Port jminta’s kill-rdf to SeaMonkey where applicable
- Landed the 6 simple patches :-)
- 1 last patch waits for 2(++) major ports:
- bug 444913 Port |Bug 413781 – XBLify folder-selection menus| to SeaMonkey
- mcsmurf replied he believes we don’t have enough review resources for this currently.
- bug 507601 Port |Bug 414038 – Replace rdf-driven folder pane with a js-driven/non-rdf treeview| to SeaMonkey
- Landed the 2 simple patches :-)
- Filed bug 510793 Actually change folder pane from rdf to js, in SeaMonkey
- Current time target would be between b2 and final…
- Filed bug 510685 SeaMonkey does want a fix for |Bug 464973 – “Expanded Columns” in the folder pane are no longer available|, unlike Thunderbird
- Filed bug 510646 Tracking future bugs for “Port |Bug 414038 – Replace rdf-driven folder pane with a js-driven/non-rdf treeview| to SeaMonkey”
- bug 507676 Port |Bug 435804 – Remaining rdf cleanup for FilterListDialog| to SeaMonkey
- bug 509324 Port the thread pane / folder display refactoring from bug 474701 to SeaMonkey
- “Triaged” patches and blocking bugs of bug 474701.
- KaiRo confirmed only one (big) patch needs to be ported for this bug.
- Fixed SeaMonkey bugs:
- bug 506850 [MacOSX] mochitest-chrome: test_action_keys_respect_focus.xul reports “Test timed out”
- bug 509594 [SeaMonkey] mochitest-plain: test_datepicker.xul fails now, conflicts with SeaMonkey (extension) ‘QA’ menu
- bug 509847 SearchDialog.js: “Warning: assignment to undeclared variable searchFolderURIs”
- bug 510716 Port |Bug 421781 – Remove fake-account hooks from front-end| to SeaMonkey
- And working on other areas… like
- infrastructure to run tests
- filing bugs for leaks in (TUnit) tests
- doing a Windows comm-central-trunk SeaMonkey unit test build, reporting to bug 470184 issue tracking; looking forward to an official build when enough new buildbot slaves can be enabled (bug 464325 follow-ups).
- Do we have enough machines for when we branch?
- We are already running a configuration that is build-wise the same as having an actual branched setup, and in terms of having builds for trunk and branch, we have things up and running.
- In terms of running tests on both, we are at least missing two machines which were promised to us, KaiRo is working with IT and community giving to get that resolved.
- But even with those machines, we’ll be overloaded unless the machines magically get significantly faster. We’ll need to take a deeper look into what to do about that later.
August 26, 2009 03:00 AM
Thunderbird/StatusMeetings/2009-08-25
From MozillaWiki
last meeting | index | next meeting »
Thunderbird Meeting Details :
- Autoconfig process
- Webapp currently being tested to fix some initial problems, will open up for broader testing soon, i.e., move the webapp to a place where more people can access it.
- Note: SeaMonkey requests that mailnews/ and suite/ strings are frozen between Thursday 27th August 23:59 PST and Tuesday 2nd September for their 2.0b2 release.
- Standard8 has checked [has l10n impact] bugs – all appear to be specific TB strings only.
- If you need to land strings bugs during that period and are unsure what to do, check with Standard8.
- Freeze Dates:
- Slushy Code Freeze: Monday 7th Sept 23:59 PDT.
- Full String Freeze: Wed 9th Sept 23:59 PDT.
- Code Freeze: Friday 11th Sept 23:59 PDT.
- l10n Complete: Monday 14th Sept 23:59 PDT.
- Release builds start: Tues 15th Sept.
- Blockers/Wanted
- Proposed Blocking (all milestones)
- Fixed:
- Release Driver: Standard8
- Build Engineer: gozer
- Schedule (proposed, may change nearer b4):
- Final l10n String Freeze: Tuesday 29th Sept 23:59 PST
- Approvals/Blockers only: from Tuesday 6th October 23:59 PST
- Aiming to start RC1 builds on: 3rd Nov.
- Subsequent RCs as necessary.
- Blockers
- Proposed Blocking
- Wanted
- Please set bugs to assigned status (as well as owner to you) if you want to do them.
- If you have other bugs assigned to you that you don’t want to do, please reassign or discuss with drivers.
- 2.0.0.23 is out !
- Continuing work on cleaning up bugzilla
- We will start presenting the people doing some of the QA to the public in september
- Need to start getting new people on board between b4 and final
- Final Icon iteration Last chance for feedback. Will get smaller sizes this week and wrap it up.
- Top articles this week Will be publishing these via SpreadThunderbird going forward.
- Coordinating launch activities with PR team.
- Windows: Microsoft Exchange 2007 up and running for testing
- hg.mozilla.org had reliability issues last week
bug 511258
- Lots of spurious bustage as a result
- The bug is closed, but we are still seeing intermittent issues
- Thunderbird 2.0.0.23 went live on www.mozillamessaging.com
See graphic below for stats Tuesday August 18, 2009 to Monday August 24, 2009, will provide more commentary and pull out selected stats for September 1, 2009 meeting.
- last week
- driving
- message header coding
- started working on review backlog
- this week
- message header coding
- reviews
- sec meeting plan
- Reviews & Driving
- Find & Zoom
- bug 510760 Fix find in new message not working on message tabs when preview pane not shown.
- bug 495922 Implement zoom on collapsed threads and summary pane (and fix zoom not working on message tabs when preview pane not shown).
- Content Tabs
- bug 503299 window.close() from a content tab closes Thunderbird window.
- bug 512245 Implement tab persist for content tabs.
- LDAP Autoconfig (bug 502597)
- Found a simpler solution of moving some files into the LDAP code base. Need to chat with dmose about this solution.
- Misc
- bug 491921 Fixed up the mozmill js content policy test – still need to do tests for the other content policies.
- bug 508694 Don’t show the summary pages for newsgroups as we don’t get useful summary text (we’ll turn it back on for offline newsgroups once we get bug 478167).
- bug 511847 [autoconfig] Setting invalid hostname then correcting can lead to -1 being displayed in insecure notices.
- Facet for gloda, patch in a “couple” of days.
- Reviews and Driving
- Trying to setup environment to test SSPI crash
- Potential fix for top crash in nsMsgDBView::FindHdr bug 503854
- Don’t create duplicate Archives folder if there’s an existing archive folder (i.e., folder with a different case name), bug 484329
- Fixed indentation level for threaded quick search views, bug 505967
- Ignore folder deleted notifications if the account/server was removed, bug 500970
- Fixed imap undo from gmail trash, and when the source folder has been expunged, and add unit test,bug 323875
- Add null check to fix crash in nsImapMailFolder::RenameClient, bug 486485
- Fixed gloda indexing stopping when some other activity clears the msg folder’s cached db, and add a test case bug 511609
- fix bug 505974, crash in OnItemRemoved deleting a local folder with saved search sub-folders
- Fixed localized special imap folders when creating account with new auto config wizard,bug 508026
- Build
- Signing
- Completed dry-run of signing automation successfully
- Release automation
- Initial testing looks very promising
- Will be running live release tests in staging this week
- hg.mozilla.org had reliability issues last week
bug 511258
- Lots of spurious bustage as a result
- The bug is closed, but we are still seeing intermittent issues
- l10n repacks suffered too as a result (busted checkouts/clones)
- Infrastructure
- Setup initial Windows test farm
- Domain Controller
- Microsoft Exchange 2007
I’ve got one risky patch still in review (bug 127250 “Body” filter for IMAP messages downloaded for offline use) that drivers may want to examine, as this patch needs to land a least a week before any code freeze due to its risk. Postponing until 3.1 would not break my heart, but it would increase the total work involved. I’ve got another few bugs in review that I am less concerned about though are important to me, including:
- bug 496015, which adds the final hooks needed for minimal junk support in news.
- bug 511131, which exposes the full search capability to users in the advanced search dialog.
I’ll still be cleaning up issues as I find them in the areas that I work in plus helping out a little in blockers, but otherwise a lot of my attention will be shifting to getting my extensions re-released, which mostly serve as demonstrations of new back-end features of TB. I’m also starting to organize collections of junk mail in preparation to support a shared junk file using the features of bug 506397 “Support multiple spam corpus files”.
- Coordinating with PR team for launch activities.
- Task list, web site content updates, product demo, reviewer’s guide.
- Wrapping up icon, starting discussions on swag/promo materials for launch.
done:
- 2.0.0.23 testing for release
- QA event
todo:
- Working on upcoming test day
- start trying to get a few more people on board.
- This week
- Continue Unclutter gnomestripe bug 505721
- Gloda faceting look & feel
- More Vista fixes now that a bunch got into trunk.
- Look into account sizes some more bug 416263
Last week:
This week:
Last Week:
- integrated Get Satisfaction (GS) widgets into support page, awaiting Silver Orange design tweaks before pushing live
- support backlog on GS, managed to do about 5-10 per day
- 1st GS day, August 20, wrote README to help new folks
This Week:
- move support content from mozilla.org to mozillamessaging.com
- more GS backlog reduction
- more GS How Tos including editing README, tagging convention
- formal support plan
bwinton, roland, davida, bienvenu, standard!, _Tsk_, gozer, clarkwb, Kairo, rkent, dmose, rebron
August 26, 2009 03:00 AM
Platform/2009-08-25
From MozillaWiki
« previous week | index | next week »
Firefox 3.0.14 / Firefox 3.5.3
- in QA, builds available
- targeting release for early/mid September
Firefox 3.0.15 / Firefox 3.5.4
- schedule set
- please work on your blockers
- code freeze is September 22
Firefox 3.6a1
- Active Daily User numbers stabilized
- 13,000 on Firefox 3.6 Alpha 1
- 5,000 on Namaroka nightly builds (2k on mozilla-central nightlies)
Firefox 3.6b1
- string-frozen (need dates and deadlines)
- co-ordinated with Fennec RC?
- component leads need to identify P1 issues for this beta
Gecko 1.9.2 / Namoroka
- Release Blockers (flag: blocking1.9.2 or blocking-firefox3.6)
- Approvals
- see our active projects and get involved / propose others
- published initial draft roadmap for product deliverables through the end of 2010
- for Namoroka/mozilla-1.9.2:
- looks like it will be possible to integrate Personas for Firefox 3.6
- also looking at protecting users with out of date plugins, see our current ideas
- also looking at Ts and Tsnap priorities
- for future/mozilla-central:
- last call for comments on the multitouch JS API prototype work (see proposed DOM events)
- identifying places where animation in the browser would help the UX (blog post coming)
- new UI mechanism for application notifications (see the spec)
- drafting a set of core principles for Firefox development; currently messy, hope to have something to publish later this week
- building product feature roadmap through the end of 2010
- Planet Firefox is up and a good source for posts about ongoing front-end development
- Decode-on-draw bug 435296
- Preliminary review done by joe and addressed by bholley
- ready for formal review
- CSS Transitions close to landing (dbaron)
- Harfbuzz running on Windows (jfkthame)
- Ongoing SVG animation improvements (birtles, dholbert)
- Fixing compositor regressions (roc)
- 1.9.2
- Trunk:
- Fixed some COW wrapper followup bugs.
- XBL2: Jonas is done with his GetDocument/GetOwnerDoc/GetCurrentDoc audit and changes to the layout code. Need to get this in soon to avoid severe bitrot.
- Henri is continuing to make progress towards moving parts of the HTML5 parser off the main thread.
- mrbkap’s got a proposal for a Jetpack security model.
- just merged a bunch of things, should be perf wins and Google Docs regression fixes
- nanojit merge almost complete, still a 500-line delta or so.
- tracing native getters almost landed
Weekly summary is here.
Plugins:
- karlt and jmuizelaar will work on windowless plugins (linux+windows)
- josh meeting with Safari/webkit developers about OOP plugins on mac today
Fennelectrolysis:
- graphics still pending (joedrew)
Necko:
- Still some hiccups with necko protocol init
- design meeting this week
Other:
- mrbkap to implement on a cross-process JS wrapper
- getting new n810s into production; uphill struggle
- new small/med dirty profile talos suites
- removed tp3, fasttalos suites
- l10n nightly updates
- on m-c, 192
- causing delays in en-US nightly updates
- 191 on hold, while we sort out bottleneck, worried about looping the day
- moved some fennec tests to VMs
- splitting of production-master/production-master02 went well
- ironing out sharing of slaves, watching wait times
- Are we going to have a status192 flag or not? It’s not clear what the outcome of the last discussion was.
- compiler change: Linux m-c builds to move from GCC 4.1 to GCC 4.3.4 sometime when I can close the tree for a few hours (bsmedberg)
August 26, 2009 03:00 AM
We could use help testing AMO 5.0.9; if you want a lightweight way of helping out, please run any of...
August 26, 2009 02:49 AM
Snowl 0.3pre3, the third preview release of the next version of Snowl (the messaging-in-the-browser experiment), is now available. This version includes a few new features and a number of bug fixes.
In the river view, you can now see a day, a week, or a month’s worth of messages via the time period picker in the toolbar:

In the list view, you can now see how many new/unread/total messages you have, and both messages and collections can have icons indicating various states (new, refreshing, error, etc.):

Other enhancements include performance improvements and better support for searching for messages in non-English languages.
This is the last preview before the final release of 0.3. From here until that release, the focus will be on bug fixes and polish.
Try out Snowl 0.3pre3 and let us know what you think! But don’t forget that this is a preview release of a labs experiment, not a stable release of a finished product, and there are bound to be bugs and other issues.
Post your thoughts on Snowl to the discussion group, and file bug reports on the problems you encounter. Or join us for discussion in the #labs IRC channel on irc.mozilla.org. And if you’re interesting in hacking on Snowl, check out the source code.
- Myk Melez on behalf of the Snowl team
August 26, 2009 12:22 AM
August 25, 2009
The best way for users to stay safe online is to use an updated browser. While most Firefox users get updated quickly, some fall behind for various reasons. We’re looking for ways to increase uptake while still preserving user choice.
Ken Kovash and Eric Hergenrader surveyed users who have update-checking enabled but repeatedly chose not to update from Firefox 2 to Firefox 3. Read their posts: Why People Don’t Upgrade Their Browser – Part I and Part II. It’s great to understand why these people continue to use Firefox 2 even when it is no longer receiving security updates.
August 25, 2009 10:29 PM
We will have a scheduled maintenance window tonight from 9:00pm to 11:00pm PDT. The following changes will take place:
- 7:00pm PDT (0200 UTC) The Amsterdam Reboot. We’ll be turning down services in Amsterdam and pulling production traffic back to San Jose in preparation for The Amsterdam Reboot next week. No user facing downtime is expected.
- 8:00pm PDT (0300 UTC) Layer42 BGP turnup. We’ll be turning up BGP peering with Layer42 and pushing production traffic through Layer42. No downtime expected.
- 9:00pm PDT (0400 UTC)
www.mozilla.org relaunch. We’ll be pushing out a new version of www.mozilla.org. See bug 510267 for details. Duration 30 minutes.
- 9:00pm PDT (0400 UTC) PHP upgrade. We be upgrading PHP on
addons.mozilla.org. See bug 506703 for details. No downtime expected.
- 9:00pm PDT (0400 UTC)
addons.mozilla.org EV SSL certificate deployment. We’ll be replacing the wild card certificate with a VeriSign EV SSL certificate tonight. No downtime expected.
Please let me know if you have any reason why we should not proceed with this planned maintenance. As always, we aim to keep downtime to as little as possible, but unexpected complications can arise causing longer downtime periods than expected. All systems should be operational by the end of the maintenance window.
Feel free to comment directly if you see issues past the planned downtime.
August 25, 2009 10:06 PM
Did you ever wonder what types of projects interns work on during their internship at Mozilla? If so, you've now got the chance to be in the front row and watch the interns chat live about their projects on
Air Mozilla. We'll be having the following interns presenting this week:
* 08/25 at 1pm PST
Aaron Train(QA)
RJ Walsh (Web Dev)
David Tran (IT)
Anant Narayanan (Labs)
* 08/27 at 2pm PST
Jeremy Hiatt (L10n)
Matthew Noorenberghe (Firefox)
Irina Calciu (platform)
Can't make it? Don't worry, we're also going to have the videos available on the interns website in a few weeks.
August 25, 2009 08:02 PM
Here's a summary of SeaMonkey/Mozilla-related work I've done in week 34/2009 (August 17 - 23, 2009):
- Releases:
After I could fix at least one major problem on the Linux 1.1.x build box (something is still strange with nightlies), I started the release process for SeaMonkey 1.1.18, which has a major upgrade of NSS (and NSPR) as the only major change, which fixes a few SSL issues, including possible MITM of SSL connections. We found a regression on Windows, failing to package some new files coming up with that upgrade and rendering NSS unusable, we're fixing this right now and doing a second round of candidates with it.
A 1.1.19 in a few weeks will then catch up with other fixes ported from Firefox 3.0.13 and 3.0.14 (the NSS we ship now is exactly the same as in those versions).
I also filed a bug on 2.1a1 as well as 1.1.19 flags on Bugzilla, we now can mark things we'd like to see fixed in those future milestones. - Build System:
Even more review for Serge's patches for porting build system changes to comm-central and and some, but not much progress in filtering out the to-be-ported changes in my new tool. - Various Discussions:
Tabmail, Mac build boxes, AMO and SeaMonkey, QA team, www.mozilla.org planning, Mozilla Camp Europe, Mozilla Creative Collective, SUMO browser sniffing, doorhanger notification plans, Thunderbird schedules, etc.
I've been quite busy this week with a halfway-finished move in real life, but things are moving well along even with me not being around as much as usually and I'll be back for the usually amount of time every week when the move is completed.
By the way, I just did get some interesting numbers about SeaMonkey 2 usage: Over the last week, we had ~2700 people average daily users on 2.0 Beta 1, about 500 on the alphas, ~460 on 2.0b2pre builds, ~150 on 2.1a1pre, and ~160 on "pre" version from before 2.0b1 - a total of almost 4000 daily users on our current unstable versions and in August, where many people are probably still on holidays. I think those are pretty decent numbers, esp. as there is a 25% rise in total numbers compared to 4 weeks earlier.
August 25, 2009 07:55 PM
After having good success two weeks ago running mochitests on my windows mobile device using a remote web server, I have cleaned up a lot of my code and made this a better process. When I last posted, I had this remaining list of action items and I have appended my status:
* Sort out python script to generate mochitesttestingprofile and get it on the device- bug 512319
* Fix profile and tests to remove localhost/127.0.0.1 dependencies- bug 512319
* Fix tests to remove calls to local files (an example I found)- about 100 test files fail
* Test on a release build of Fennec with desktop tests.tar- more details below
* Verify tools like certutil.exe, ssltunnel.exe, etc.. do not cause any problems- no progress
* Write tools in the python script to look for a test that doesn’t exit and clean up zombie processes- fixed with maemkit
I have yet to update maemkit officially, but that is in the works. I mentioned there is a quirk with running on release build and tests.tar. The issue with this is to make sure you have the right build and binaries for the right platform. I know this sounds easy, but in order for me to run tests on windows mobile, I need to build a binary of windows mobile and a test package for desktop.
Let me outline a set of steps that are necessary to take to help elaborate on this:
1) Build WinMo build and install on device (I usually take the .zip file, unzip, and copy to \tests\ so that I can run \tests\fennec\fennec)
2) Build Windows Desktop build (with my two patches 508664 512319) and create a ‘make package-tests’ and untar this in something like c:\tests (so you have c:\tests\bin, c:\tests\mochitest\, etc…).
3) Using the build from step #2, create a ‘make package’ and unzip the package to c:\tests so you have c:\tests\firefox\firefox.exe.
4) Copy c:\tests\bin\* c:\tests\firefox so we have the xpcshell.exe in the correct directory
5) Run: python runtests.py --appname=firefox.exe --remote-webserver=192.168.55.100:8888 --setup-only. Note the ip address is the activesync ip
6) Create profile directory on device: c:\tools\pmkdir.exe \\tests\\mochitesttestingprofile\\
7) Copy mochitesttestingprofile to device: c:\tools\pput.exe -r c:\tests\mochitest\mochitesttestingprofile\* \tests\mochitesttestingprofile\
7) Edit httpd.js and server-locations.js in c:\tests\mochitest to change localhost and 127.0.0.1 to be 192.168.55.100
 Launch web server (from the c:\tests directory):
Launch web server (from the c:\tests directory):
firefox\xpcshell.exe -g firefox -v 170 -f mochitest\httpd.js -f mochitest\server.js
9) launch fennec on remote device:
c:\tools\prun.exe -w \tests\fennec\fennec.exe --environ:NO_EM_RESTART=1 -no-remote -profile \tests\mochitesttestingprofile\ http://192.168.55.100:8888/tests/toolkit/components/passwordmgr/test/test_xhr.html?logFile=%5ctests%5cmochi.log
That is the basic run. When I have maemkit updated, step 9 would become:
python maemkit-chunked.py --testtype=mochitest
I can automate a lot of these steps if I assume we are running over active sync and make maemkit a bit smarter about the setup.






August 25, 2009 07:54 PM
As promised, here is the second post from Jeremy Hiatt’s work on our l20n project. This is a word-for-word reposting of his essay about compiling localizable objects in native JS.
====================================
One of the goals for my summer internship is to improve performance of l20n. The initial implementation was a parser written entirely in JavaScript that operated on .lol files. For more details about our choices for file formats, see my previous post. After some failed attempts to rework the parser’s use of regular expressions that regressed performance, I experimented with JSON as an alternative file format. The hope was that we could leverage the performance of Gecko’s built-in JSON parser to speed up l20n. We did see some tremendous improvements: on a large testcase constructed from browser.dtd, JSON cut our parsing time from ~140 milliseconds down to just a few ms. Unfortunately, we were still slow when it came to evaluating and displaying all those entities. We still had a big chunk of parsing left that we couldn’t outsource to JSON. Each string value in l20n may contain variable placeholders. Here’s an example (in JSON):
"droponbookmarksbutton" : {
"value" : "Drop a link to bookmark it"},
"popupWarning" : {
"value" : "${brandShortName}s prevented this site
from opening a pop-up window."}
(Line breaks inserted for clarity.) The first string doesn’t use any variables, but the second does. In order to catch all these placeholders, we scanned each string with a regular expression to match the ${…}s syntax, even though many strings don’t use any variables. That translated to a linear traversal of every single string before it could be returned, costing us a lot of time. In tests conducted in the xpcshell, rendering all the elements from browser.properties took roughly 40ms. In comparison, the current framework for properties files can parse and display all the elements in under 20ms. Since we can’t afford to regress overall performance, that meant we still had work to do to get faster.
One way to eliminate checking every single string is to add extra information to the encoding for strings. Many languages define different behavior for single- vs. double-quoted strings, performing replacements in one but not the other. We could also have added a special flag to indicate simple (no replacements) vs. complex strings. Either of these approaches would have added further complexity to the localization process, so we did not seriously consider this approach.
Instead, on the advice of the brilliant Staś Małolepszy, we embarked on an experiment to compile our l20n objects into native JavaScript. As a result, we saw another impressive performance jump. In an xpcshell test, we can load and display all of browser.properties in roughly 4ms (an order of magnitude improvement!). Here’s what our previous example looks like as compiled JavaScript:
this.droponbookmarksbutton="Drop a link to bookmark it";
this.__defineGetter__("popupWarning",
function() { return "" + (brandShortName) +
" prevented this site from opening a pop-up window.";});
Another great thing about compilation is that our runtime performance doesn’t depend on our choice of source file format. Here’s a diagram showing the different ways an l20n file can get inflated into a localization context:

Inflating l20n source into a context
The performance numbers were collected using nsITimelineService in the xpcshell. The l20n runtime infrastructure can inflate a source file directly into a context, or it can load compiled JavaScript definitions for a significant performance boost. For comparison, here’s a diagram of Mozilla’s current l10n scheme:

Current l10n scheme
Again, this time was measured in the xpcshell when loading the browser.properties string bundle. It’s not necessarily representative of performance for DTD files as well. As we can see, compilation now guarantees at least comparable performance to the current approach, no matter what file format we end up using. If you’d like to weigh in on that debate, please leave a comment on my previous post! And finally, we are also working on l20n support in Silme so that it will be easy to migrate existing DTD/.properties files to our new l20n format.

Intercompatibility with Silme
Silme will serve as a critical compatibility layer to ensure a smooth transition to our new l10n framework. Please let me know if you have any questions or comments!
ShareThis
August 25, 2009 03:59 PM

Promotion and growth
Recently, Alix Franquet arranged for the about:mozilla newsletter to be featured as one of the Firefox Start Page snippets. Prior to this, the newsletter had plateaued at around 2800 email subscribers (plus an unknown number of readers via the web and feeds), increasing by maybe 10-20 subs per week. Since being added to the start page, however, the number of email subscribers has exploded to 6800, and the number continues to grow by 300-500 subscribers every week. A million, million thanks to Alix for helping promote the newsletter like this.
Content and length
The newsletter has also been getting longer as the Mozilla Project continues to grow both in the sheer number of contributors and the number of projects being undertaken. I’m going to experiment with slightly increasing the number of stories mentioned while paring down a little on the number of words I write per piece, to see how that works.
Experimental source feed
I’ve also started an experimental “Source feed” of sorts. Each week, while I read through the various Mozilla-related news sources, I flag possible items for newsletter inclusion by starring them in Google Reader. A few weeks ago I also started “sharing” those items, so you can now see a raw feed of Mozilla news stories, mentions, and blog posts that I’m thinking about including in the newsletter. I’m not sure whether it will be useful or not, but someone asked if I could put it together, so here it is.
That’s about it for now. If you have any questions or suggestions about the newsletter, please feel free to leave a comment here or email me at deb-at-mozilla-dot-com.
August 25, 2009 03:44 PM
I’m kicking around ideas for a project that shall currently remain nameless, and need a bit of your help. Yes, your help.
Specifically, what’s the next awesome thing? For example, at one point ninjas were frequently used as shorthand for awesomeness but are now a bit passé (even if they’re still pretty awesome).
With that in mind, I’m trying to figure out what the next thing will be. Please leave your awesome ideas (as many as you want) in the comments section. Thanks!
August 25, 2009 03:05 PM
This is the second in a series of ‘notes’ posts about Mozilla Drumbeat. It rolls in thoughts from people listed at the top of my last post plus Gina, Joi, Asa, Jim, Ronaldo, Sunil and Bruno. Mostly, it focuses on the question: what big Internet topics and issues should Drumbeat tackle?

1. There is broad agreement that the framing issue for Drumbeat is ‘protecting the Internet as public commons’ (or ‘public asset’). However, most people also agree that this way too broad a topic to start engaging people around.
2. There is a short list of topics that seem to be in Mozilla’s ’sweetspot’ -> privacy and security, identity and data, mobile ecosystem, open video, open standards. Mozilla is already working on all of these issues on the product side. Most people agree that this makes them good candidate topics for the broad conversation and consumer engagement planned through Drumbeat.
3. A number of other issues come up regularly but fall outside of Mozilla’s traditional focus. Examples are net neutrality (network layer) and copyright (content layer). A number of people have suggested we debate whether topics like this are in scope or out of scope.
4. The tough part is narrowing down from these broad topics into very specific concepts that we can build events, campaigns and training materials around.
5. Deciding where to focus and getting more specific will be easier if we have a set of ‘topic selection criteria‘. Possible criteria include:
a. Major issue that will impact the future shape and nature of the web. This is obvious, but still worth stating as the primary criteria.
b. Strong connection to issues product teams working on, but could benefit from more thinking and consumer action. E.g. security is focus in products, but consumer awareness and action could take us further.
c. Not too early, not too late. There needs to be enough awareness that an issue is important, but still early enough we can make an impact. Identity, data and freedom in the cloud feel like good examples here.
-> These are just starting point for discussion. Criteria need to be elaborated quite a bit still.
6. Also need to decide whether to focus Drumbeat narrowly (one major theme issue per year) or more broadly (let ideas and issues bubble up from broad framework above). Talking to people, two major approaches emerge:
Approach A: Start with broad topics like privacy and identity, and then let more focused ideas and campaigns bubble up from the community. Plugged into the framework in my last post, this would mean feeding a number of topics into small events and online community, and then running one or more large events based on the strongest themes and ideas that emerge. Could use ‘ideastorm‘ type approaches for some of the early online and small event conversations.
Approach B: Start by identifying a singly yearly theme, dig into it and then push out ideas that people can run with. In this case, we would probably start with the a large annual event on a hot topic (e.g. identity), write up a white paper and other documents, and then use that drive engagement through small local events and our online community.
-> In either case, the topics should be concrete (e.g. security or open video). The decision to be made is whether to start broadly with a number of topics, or to start by picking one yearly topic and drilling down.
7. The ‘hot issues’ are different in different parts of the world. Most of the people I talked to in North America were drawn to some overlapping set of privacy / identity / data in the cloud. People I talked to in India and Brasil focused more on the role mobile will play in shaping the future of the Internet.
More notes planned for coming days. Will focus on digging deeper into each of the three framework elements (local events, big events and online community). Also, I have a bunch of notes on working with existing orgs and communities around the world.
Posted in drumbeat, mozilla






August 25, 2009 02:31 PM
In this issue…
Mozilla Creative Collective launches
John Slater and Tara Shahian have announced the launch of the new Mozilla Creative Collective (MCC). “Building communities is a big part of what Mozilla is all about and key to our success as an organization. We have dedicated communities that contribute to nearly every aspect of Mozilla — from software development, to extensions, to localization, to marketing, and more — but an idea that’s traditionally lacked an organized community is visual design. And because art is such a powerful form of communication, we’re harnessing that with the Creative Collective.”
On the Mozilla Creative Collective website, users can create profiles, share their visual design work in a public gallery, mark various designs and artists as favorites, earn achievement badges, connect and collaborate with others from around the world, and much more.
The Creative Collective is also working with the Mozilla Service Week team on a Design Challenge. “We’re hoping your creativity and artistic skills can help inspire action and ultimately better the Web experience for people and organizations around the world.” The Design Challenge announcement has some ideas to spark your creativity and all the information you need to get involved now.
Mozilla Service Week: Act now!
Mozilla Service Week — a week during which the Mozilla Community is rallying to donate their time and skills to help change people’s lives and make the Web better for everyone — is taking place Sept 14-21 and coming up soon! Mary Colvig, the organizer and driving force behind the project, has written up a quick guide to what you can do right now to get involved and get started, including: register for the event, pledge some hours, share your story, blog, tweet, invite your friends to the Facebook event, put an affiliate button on your weblog, and more. If you’ve ever wanted to get involved with the Mozilla project or give back to the community and support the open web, Service Week is a perfect opportunity. Check out the site and get involved today.
Extend Firefox 3.5 contest!
The Extend Firefox contest is back, challenging developers to make the next great web experience. The contest awards prizes for developing new Firefox add-ons for the latest production release of Firefox. Last year’s contest received over 100 submissions and, with Firefox 3.5 raising the bar in terms of features, you can expect this year’s competition to be intense. For more information, see the original Extend Firefox 3.5 contest announcement. The contest is currently open and runs through October 2nd, 2009.
New Mozilla Labs website
Mozilla Labs unveiled a new website last week, including a whole new look and feel and new independent sites for each active Labs project. It’s easier than ever to stay up to date on Labs development, get involved with the projects, contribute to the design discussions, and participate by writing patches, doing testing, or helping with documentation. Mozilla Labs is always working on new and innovative projects, and is a fantastic way to get involved with the Mozilla project.
BBC experimenting with open video
The Mozilla Hacks team reports, “The BBC has a post up describing an experiment that they have put together that uses HTML5 video that works in Firefox 3.5 and Safari. The demo uses jQuery and drives a simple carousel that shows the current chapter as the video plays. It also shows subtitles as the video plays.”
Web accessibility and CSS3 transforms
Marco Zehe, part of the Mozilla Accessibility team, has posted an interesting fact about CSS3 transforms. “If you’re one of those people who likes to visually twist, rotate or tweak some text, in previous years the only real choice was to use pictures to achieve such visual effects. However, thanks to CSS3 transforms — supported in Firefox 3.5, Safari 3, and Opera 10 beta — it is now possible to use plain text and rotate, twist and tweak its looks via CSS. The big advantage: Screen readers will still read the text OK because their reading order is not influenced by the visual appearance of the text. So even text rotated by 45 or 90 degrees will appear correctly in a screen reader’s virtual buffer.”
Jetpack developer contest
Mozilla Labs is hosting a new developer contest, this time focused on the Jetpack project. “Jetpack is an experiment in using open Web technologies to enhance the browser, with the goal of allowing anyone who can build a Web site to participate. In preparation for the [upcoming 0.5] release, we are launching a Jetpack contest. For making the coolest or most interesting Jetpack, we are offering a brand new netbook (the ASUS Eee PC 1000HE). For the runner-up, we’ll send you a big package of Mozilla swag.” For more information about the upcoming Jetpack release, the contest, and how to get involved, see the contest announcement over at Mozilla Labs.
Fennec 1 beta 3 for Maemo
The Firefox Mobile team has announced the release of Fennec beta 3 for Maemo. “This release features major improvements to performance and a fancy new theme. We’ve made big improvements to kinetic panning and added the ability to scroll iframes. A lot of work has been done to make the theme more robust, taking advantage of things like media queries to support various devices, orientations, and platforms which you’ll see more of in the next Windows Mobile release.” In addition to the Maemo build, you can also download desktop builds for Windows, Mac, and Linux. If you would like to see some screenshots, Madhava Enros has put together a slideshow over on his weblog.
AMO upcoming projects
The addons.mozilla.org (AMO) team has been hard at work cranking out features like Collections and Contributions, and they have now posted about some upcoming projects. These include Collections Phase II, a new Add-on Developer Hub, Disclosure of add-on practices, and an Add-on compatibility reporter. For more information about these projects and more, see the AMO weblog.
Multitouch in Firefox
Felipe Gomes has posted an article, including a video, demonstrating the progress he’s made on developing multitouch support for Firefox during his summer internship here at Mozilla. “We’re working on exposing the multitouch data from the system to regular web pages through DOM Events, and all of these demos are built on top of that. They are simple HTML pages that receive events for each touch point and use them to build a custom multitouch experience.” Read more about Filipe’s amazing work, view the video demonstration, and see an API example over at his weblog.
Firefox accelerometer support
Doug Turner has recently added support for an orientation event to recent trunk builds of Gecko. “This new event will allow you to build applications and listen for changes in orientation.” This takes advantage of accelerometers that are a feature of many modern devices. “Right now, there is only support for the Macbook Pro. It is pretty easy to add support for different OSs. We have code for Samsung Windows Mobile devices, and for the HTC Windows Mobile devices. We still need support for Linux and for Windows. If you are interested in adding support, file a bug and start looking at the code. The API isn’t fixed and may change.”
Mozilla Drumbeat
Mark Surman has posted about the feedback and discussions around the “next million Mozillians” thread that he started last month. “Some are saying: ‘let’s clarify and communicate what we’re actually trying to achieve here.’ The best clarification so far: ‘we’re starting a drumbeat for the open web.’ Based on this, I am proposing we use ‘Drumbeat’ as an umbrella code name for the collection of new community engagement ideas being developed.” Mark has also posted the first of a series of follow-up articles around the “Drumbeat” theme.
Everyone is encouraged to read through these posts (and the “next million Mozillians” posts before them) and take part in the developing conversation. This is an essential part of the evolution of the Mozilla project, and having more people help guide and shape that future is critical for its success.
Proposed Microsoft-EC settlement
Mitchell Baker and Harvey Anderson have both posted their reactions to Microsoft’s proposed settlement in the European Commission’s tying investigation. “Asa Dotzler did an evaluation of the proposal, noting both items that appear promising and those that appear weak. In all things the implementation details — all the way to the most mind-numbing level of specificity — will have an immense impact on the proposal’s effectiveness, so we’ll have to wait and see what those details turn out to be.” Mitchell goes on to outline a few aspects where the proposal could use improvement.
“The overall point that may get lost is that — even if everything in the proposed settlement is implemented in the most positive way — IE will still have a unique and uniquely privileged position on Windows installations.” For more, see Mitchell’s and Harvey’s weblogs.
Thunderbird 3 beta 4 schedule
The Thunderbird development team has posted the freeze schedule for the upcoming Thunderbird 3 beta 4 release. “We’ve still got a lot of blockers in the list, some of them are currently un-owned. If you wish to write a patch for a bug please do so. If you can, help out with bug triage, writing test cases and test days. See the QA page for more information.” The team is also working on their documentation, and point you to Jen’s blog to find out how you can help.
Upcoming events
The Mozilla community is organizing an increasing number of events and meetups all the time, and we include a list of these here every week. If you have events you would like listed, send them along to: about-mozilla*at*mozilla.com.
* Thu, Aug 27 – Mountain View – Labs Night
* Fri, Sep 4 – Online – Firefox 3.5 Testday
* Sept 14-21 – Everywhere! – Mozilla Service Week
* Fri, Oct 2 – Everywhere! – Extend Firefox contest deadline
* Oct 3-4 – Prague – Mozilla Camp Europe
* Oct 15 – Everywhere! – Jetpack contest deadline
* Nov 7-8 – Sofia, Bulgaria – DevGarage
Developer calendar
For an up-to-date list of the coming week’s Mozilla project meetings and events, please see the Mozilla Community Calendar wiki page. Notes from previous meetings are linked to through the Calendar as well.
About about:mozilla
about:mozilla is by, for and about the Mozilla community, focusing on major news items related to all aspects of the Mozilla Project. The newsletter is written by Deb Richardson and is published every Tuesday morning. If you have any news or announcements you would like to have included in our next issue, please send them to: about-mozilla[at]mozilla.com.
If you would like to get this newsletter by email, just head on over to the about:mozilla newsletter subscription form. Fresh news, every Tuesday, right to your inbox.
August 25, 2009 01:52 PM
Hallo !
nachdem grossen Erfolg des 1. Opensource Treffen geht es weiter !

Wie bisher wird diese Veranstaltung von Mozilla und OpenOffice.org organisiert aber auch andere Projekte haben die Möglichkeit, sich mit einem kurzen Vortrag vorzustellen und in direkten Kontakt mit ihren Anwendern zu treten.
Im Rahmen einer Idee möchten wir versuchen, die Macher und die Nutzer von freier Software zusammenzubringen – in gemütlicher Atmosphäre, ganz unverbindlich, ohne kommerzielle Hintergedanken. Die Projektmitglieder können in direkten Kontakt mit ihren Nutzern treten, um wertvolles Feedback zu bekommen, und die Anwender lernen Leute aus ihrer Region kennen, die am Projekt beteiligt sind. Die Teilnahme ist natürlich vollkommen kostenfrei und unverbindlich.
Jeder ist willkommen, vom z.b. Firefox-User, der mehr über Open Source/beispielsweise das Mozilla-Projekt erfahren und mitarbeiten moechte bis zum aktiven Entwickler, der schon jahrelang zum Erfolg von Open Source Software beiträgt.
Das nächste Treffen wird am Freitag, den 25. September, im Café Netzwerk in München stattfinden.
Mit dabei sind neben Mozilla und OpenOffice.org unter anderem OpenStreetMap und CAcert.
Zwecks Planung gebt uns bitte kurz per E-Mail direkt an info@opensourcetreffen.de bescheid, wenn und mit wie vielen Personen ihr kommen wollt ! Die Anmeldung ist natuerlich kostenlos und unverbindlich !
Wir planen auch bereits Treffen in weiteren Regionen Deutschlands, unter anderem in Berlin, Essen, Bremen, Leipzig, Stuttgart und Nürnberg. Wenn ihr selbst ein Open-Source-Treffen in eurer Gegend organisieren wollt, dann meldet euch bei uns (info@opensourcetreffen.de) !
Mehr Informationen zu der Event-Reihe gibt es hier http://www.opensourcetreffen.de
Viele Gruesse
Carsten
August 25, 2009 11:38 AM
I asked this on the mozhacks twitter account earlier today but I’d like to get more feedback:
what’s your single favorite thing about hacks.mozilla.org?
The survey is totally anonymous and takes 20 seconds or so. It’s limited, much like twitter, to a very short response. If you have ideas on improvement there’s room for that as well so please, respond away! If we get enough good feedback we’ll post results here as well.
Thanks!
August 25, 2009 04:36 AM
WeeklyUpdates/2009-08-24
From MozillaWiki
« previous week | index | next week »
Austin King wrote in “Milos Dinic – for his work on Mozilla Service Week. He contributed with a patch, filed several bugs, and helped testing the L10n release. He is the Serbian Mozilla Community Leader”
Sarah Doherty wrote “I would like to nominate Kwamena Appiah-Kubi for Friends of the Tree. He is one of our Campus Reps from Kwame Nkrumah University Of Science and Technology (KNUST) and did an amazing job organizing a group of community members to represent Mozilla at Maker Faire Africa in Accra, Ghana. Thanks Kwamena!”
Akash Desai wrote in “Kbrosnan and KenS deserve some major props for their contributions on the Fennec 1.0 Beta Testday! Specifically, kbrosnan was an advocate for the community in the channel and also filed 4 bugs on the day. Also, KenS was out top tester by running through 51 testcases on litmus for Fennec and find 1 bug on the day.”
Firefox Front End Work
Namoroka
- next milestone: Firefox 3.6 Beta 1
- still working through triage, waiting on some l10n estimates in order to get a timeline fleshed out, looking at mid-to-late September for a beta
- goals are startup time, responsiveness, Windows 7 readiness and polish
- stretch goals include things like determining if Personas can be included as well as some changes to how the updater works to include plugin updates
Team News
- this is Matthew Noorenberghe’s last week with us as a Firefox intern, he’ll be finishing up work on the new notification UI project this week
- the whole team is in Mountain View this week, hanging out in “Very Strong, Very Mighty”
- Firefox 3.0.15 / Firefox 3.5.4
- schedule, queries available on the wiki
- targeting mid-late October release
- code freeze is September 22 at 11:59pm
Target dates (subject to change):
- 3.0b4 (see Standard8’s blog post for more info)
- Slushy Code Freeze: Monday 7th Sept 23:59 PDT.
- Full String Freeze: Wed 9th Sept 23:59 PDT.
- Code Freeze: Friday 11th Sept 23:59 PDT.
- l10n Complete: Monday 14th Sept 23:59 PDT.
- Release builds start: Tues 15th Sept.
- 3.0RC1
- Final l10n String Freeze: Tuesday 29th Sept 23:59 PST
- Approvals/Blockers only: from Tuesday 6th October 23:59 PST
- Aiming to start RC1 builds on: 3rd Nov.
- Subsequent RCs as necessary.
Last Week
- hg issues
- changed Apache to spawn new thread per request
This Week
- New log processing box for metrics (im-log03)
- VeriSign EV cert for addons.mozilla.org (08/25/2009) bug 503040
- Turning up Layer42
The Amsterdam Reboot
- Will start turning down Amsterdam websites Tuesday night
- hg woes last week
- Fennec 1.0b3, TB2.0.0.23 shipped
- FF3.0.14, FF3.5.3 (with unprompted major update)
- bunch more nokias coming online
- disabled tp3
- l10n nightlies updates working fine so far
- only worries so far are some delays with en-US nightly updates, being worked on.
Test Execution
- Thunderbird 2.0.0.23 – Finished BFTs, l10n testing, and Releasetest and Release update testing
- Working on bug fix verification for Firefox 3.0.14 and 3.5.3
- Working draft Firefox 3.6 Testplan is up
- Tested and shipped Fennec 1.0 beta 3 last week
- Tegra testing now has software updates checked in, and about 800 reftests executed and running
Web Dev Testing
- Mozilla Creative Collective and Mozilla Service Week releases were shipped this week.
- Testing AMO 5.0.9 features. Added 4 Litmus test cases for login section. Also wrote 6 automated Selenium test cases.
- Verified bug fixes Sumo 1.3 and wrote litmus test cases
- Wrote Litmus test cases for Spread Firefox and mozilla.com
Metrics, Accessibility, Localization, Community
- Community:
- Held a Fennec 1.0 Beta Testday. Results can be found here
- Verified over 300 bugs last week! (thanks to aakash and joel)
- Help a Code Coverage QA meet-up last Wednesday. We had a good discussion about what works and wha tto watch out for. See Preso.
- Coordinating with Florian from OpenOffice about the next Opensource Meetup on September 25
- Accessibility:
- Reviewed bug 510441. This important for NVDA grant work on improving WAI-ARIA support.
- Marcoz became a moderator in the German camp-firefox.de community (the largest Firefox-based forum) in the newly created form “Barrierefreiheit” (German for “accessibility”). This is a great opportunity to help community members there.
- Went to the Best Practices Stammtisch Essen on Monday August 17, and gave a talk on WAI-ARIA. We looked at Accessible Twitter as an example of good usage of WAI-ARIA landmark roles. The “Best Practices Stammtisch Essen” is a bi-weekly meetup of web workers from the Ruhrgebiet area in Germany, exchanging knowledge in areas such as accessibility, HTML5 and other topics. They looked at CSS3 transforms in action. See blog about the positive accessibility impacts of using them.
- Projects Metrics (AKA Firefly)
Test Development
- Got reftests running over http (pointing tests to an external http server)
- Only three tests fail when running with Firefox
- Used this to run 800 tests on windows CE (before Firefox crashed)
- Landed JS Ref tests – you can now run JS tests in the browser using a reftest style manifest
- Worked a lot on Mobile last week
- Tags implemented for Test Case Manager, almost ready to release a preview for feedback
- More notes here
PR
Mozilla Service Week
- Overall update:
- Pledge hours are close to 4,000 (up over a 1,000 hours from last week)
- Great blog coverage – more to come.
- Featured on Case Foundation home page!
- Wondering how you can be a part of Mozilla Service Week?
- We’re still going global!
- SQ and KO going live this week
Events
- Jornadas Regionales de Software Libre en Chile October 7 – 9, 2009, Santiago, Chile – Sponsoring event and bringing together the Mozilla Hispanic Community. + 2 day MozCamp Prior.
- WordCamp Philippines September 19, 2009 in Makati City, Philippines – We are sponsoring this event. Our mission is to help build up the Philippine community and build the Tagalog locale.
- Philippine Blog Awards October 9, 2009 in Luzon, Philippines – We are sponsoring this event. Our mission is to help build up the Philippine community and build the Tagalog locale.
- Festschrift Symposium on Mitchell Wand September 19, 2009 in Boston, MA. We are sponsoring this event. Our labs intern, Brandon Pung is representing Mozilla at the event.
Community
- Currently working on two new SUMO milestones
- Mozilla Developer Center
- As always, make sure your bugs are tagged with the
dev-doc-needed keyword if they will need explaining to developers or web developers.
- Fixed at least most of the problems left over after the server glitch last week. Still sorting out the outlying cases.
- Can now sort tables on MDC, which will make many things nicer.
- Preparing to upgrade MDC to the just-about-to-release MindTouch 9.08 release.
- Dealing with crashes of MDC (it’s the database server)
- Labs Night this Thursday, 6-8pm in Ten Forward. Guest speakers will be Li Gong from Mozilla Online in Beijing, and a mystery guest speaker
- The new Labs website is live.
- We have a new beta of Jetpack 0.5, with improved security and audio support.
- We also announced a contest to write the coolest Jetpack extension (Deadline October 15).
- Weave 0.6pre, with the final Weave 0.6 release hopefully this week. It includes better Fennec UI, better error handling, and about:weave, a new web-based UI for logging in and creating accounts.
- Bespin Roadmap
- 0.4.1 Released
- Mozilla.org “Doctor”
- TestSwarm going out this week
No more Show & Tell, but a whole lot of Interns Presentations:
https://intranet.mozilla.org/2009Interns#Interns_Brownbags
August 25, 2009 03:00 AM
Jeremy Hiatt is our localization summer intern who has been doing some fantastic work to advance the conceptual idea of L20n into something more practical. Below is a word-for-word copy of a post he made on his blog. I am reposting his words to get more people reading what he has been working on. Tomorrow will come a second repost about compiling localizable objects into native JavaScript.
——————————-
L20n (for localization, 2.0) aims to empower localizers to describe complexities and subtleties of their language: gendered nouns, singular/plural forms, and just about any other quirk that might exist in the grammar. Like DTD and .properties formats, which we currently use to encode localizable strings, l20n objects associate entity IDs with string values. Localizers translate these values into the target language. L20n has all the power of the current framework, plus a lot more, and it’s just as simple to use (provided we choose the right format!). You can find some examples of l20n in action here. In the past weeks, we’ve experimented with JSON (JavaScript Object Notation) as a file format to represent localizable objects in hopes of achieving better performance by leveraging the new built-in JSON parser in Firefox. The performance gains were substantial, but still not enough to compete with the current DTD/properties framework in terms of speed. We’ve since adopted a new scheme to compile our l20n source files into native JavaScript (credit to Staś Małolepszy for suggesting this). This compilation now guarantees good performance independent of our choice of source file format. I will discuss the specifics of compilation in an upcoming post; this post will focus on the relative merits of the various formats under consideration.
Meet the contenders
LOL files
Before experimenting with JSON, we developed a novel format for l20n, playfully titled “localizable object lists” (.lol files). A lol file looks like a hybrid of DTD and .properties formats, with entities delimited by angle brackets and colons separating keys from values. Here’s a simple example, constructed from brand.dtd:
<brandShortName: "Minefield">
<brandFullName: "Minefield">
<vendorShortName: "Mozilla">
<logoCopyright: " ">
In this simple case, the lol file looks a lot like the original brand.dtd, which looks like this:
<!ENTITY brandShortName "Minefield">
<!ENTITY brandFullName "Minefield">
<!ENTITY vendorShortName "Mozilla">
<!ENTITY logoCopyright " ">
We lost the !ENTITY declaration and added a colon, but otherwise the lol format should look familiar. What if we want to do something more complex, like define an entity that involves a gendered noun? Here’s a German example encoded in a lol file:
/* This entity references a gendered noun */
<complex[appName.gender]: {
male: "Ein hübscher ${appName}s.",
female: "Ein hübsches ${appName}s."}>
/* This is a gendered noun */
<appName: "Jägermeister"
gender: "male">
In the above example, we indicated the “complex” entity depends on the “gender” property of the “appName” entity. The ${…}s expander within the string is a placeholder that will be replaced with the value of “appName” (Jägermeister). Note that we can insert comments in the familiar /*…*/ style. If you’re curious to see more use cases for l20n and the lol format, be sure to check out the link above to Axel’s examples.
JSON
JSON is a well-known data exchange format. It’s simple to understand, and with implementations available in many different languages, simple to use. As mentioned above, our initial attempt to encode localizable objects in JSON was motivated by performance concerns. Even without a speed advantage, JSON still has some attractions, namely its existing implementations. Our JSON-based l20n infrastructure leverages Gecko’s built-in parser to do a lot of heavy lifting, meaning we have less code to maintain on our part. Plus, arrays and hashes, the fundamental datatypes available in JSON, are a natural fit for localizable objects. Still, JSON has some serious shortcomings, which we will see shortly.
As mentioned above, JSON is great for describing key-value pairs. Here’s the same brand.dtd example, now expressed in JSON:
{"brandShortName" : {"value" : "Minefield"},
"brandFullName" : {"value" : "Minefield"},
"vendorShortName" : {"value" : "Mozilla"},
"logoCopyright" : {"value" : " "}}
Our localizable objects in JSON feature a “value” attribute denoting the string to be displayed. This makes our JSON example slightly more verbose, along with the required quotes surrounding the keys. Now here’s the sample gendered-noun example from above, this time in JSON:
{ "complex" :
{"indices" : ["appName.gender"],
"value" : { "male" : "Ein hübscher ${appName}s.",
"female" : "Ein hübsches ${appName}s."}},
"appName" : {"value" : "Jägermeister",
"gender" : "male"}}
In JSON, we need to reserve some keywords for attributes, like “indices” here, to implement certain l20n features. Still, JSON works pretty well to express the structure of the object. One area where JSON doesn’t work so well is comments. In JSON, our top-level object is a hash that associates entity IDs with their definitions. There are a few apparent ways to integrate comments into this object:
- Assign each comment to the same identifier, e.g. “comment”.
- Assign each comment to a unique identifier, e.g. “comment0″, “comment1″, etc.
- Don’t allow top-level comments: each comment has to be an attribute of an entity
Option 1 makes sense for humans writing JSON, and it’s valid, but a little strange.
Option 2 is a little painful when writing the file, especially when it comes to inserting new comments. This scheme would make it possible to reference specific comments, which might be useful.
Option 3 is somewhat of a straw-man but still deserves some consideration. Most comments in a localizable file give instructions for how to translate a specific entity, and now that relationship would be explicitly enforced. This form of comment is likely the best choice in most situations, but it probably is too restrictive to make it the only choice.
Another shortcoming in JSON is that it doesn’t support multiline strings. This is a serious problem when it comes to presenting long strings to localizers, since line breaks aren’t just for readability; they also give important cues for localization about logical separation between thoughts. As it turns out, the native JSON parser built into Gecko is perfectly content to accept multiline strings, but most other parsers will report an error.
YAML: A better JSON?
YAML is a data serialization language that is a superset of JSON. It supports comments, multiline strings, and user-defined data types. On the downside, it’s not nearly as well-known as JSON, it’s considerably more complex, and it’s not already built in to the Mozilla platform.
Here’s our first example from above, now in YAML:
brandShortName: Minefield
brandFullName: Minefield
vendorShortName: Mozilla
logoCopyright:
And the second example:
complex:
indices: appName.gender
value:
male: Ein hübscher ${appName}s.
female: Ein hübsches ${appName}s.
appName: {value: Jägermeister, gender: male}
YAML has the same logical structure as JSON with a much cleaner look, since indentation can be used instead of curly braces to denote objects, and it doesn’t require strings to be delimited with quotes. That’s another attractive feature, since it reduces the chance for errors with improperly escaped quotes within strings, and missing trailing quotes, that cause a lot of frustration. The less rosy side of the picture is that we don’t have a YAML parser that we can simply drop into place like we did with JSON, so it would require a lot of work on our part to get it up and running. YAML does have a fair number of implementations floating around, but development seems to have stalled on many of these. For example, this JavaScript implementation hasn’t seen any updates in nearly 5 years.
Summary
So far we’ve seen examined three choices: LOL, JSON, and YAML. The first was designed specifically for l20n, so naturally it encodes the complex features of l20n most gracefully. The remaining two are established formats with implementations available in many different programming languages (JSON to a far greater extent than YAML). The lack of comments and multiline strings is probably enough to eliminate JSON from the discussion, since these deficits outweigh any advantage of interoperability, leaving us with LOL and YAML. If you’d like to make a case for one of these, or any other format dear to your heart, don’t hesitate to leave a comment! We’d love to get your input.
ShareThis
August 25, 2009 12:49 AM
Friday is approaching fast, it will be my last official day as an intern with Mozilla Corporation, but certainly not my last day with the project and overall initiative.
The past four month’s have offered me an an incredible chance to learn, far more than any one job, classroom or book may offer. I have learned a lot; everything from the Mozilla platform to invalidation reference testing to XML User Interface Language (XUL) to reducing test-cases for crashes in the browser to even the vast assortment of brown-bag and meet-up discussions, I have learned a lot. With the knowledge gained, this internship opportunity has been far more rewarding than one could possibly imagine. There is nothing more rewarding than having the opportunity to discover and ascertain and to certainly ask many upon many questions.
Four month’s long, I worked alongside the QA (Execution & Test Dev), (that of which include Clint and Heather) team driving forth many efforts within the world of testing. Over the months, I got to tackle quite a few tricky issues that turned out to require new and unique solutions that I really enjoyed inventing and implementing. The different challenges and testing opportunities were each rewarding as they demonstrated the underlying importance of software testing.
See my parting presentation here for a complete overview (no <iframe/> in WordPress) of the major project I worked on in July/August and the test development areas I worked on in May and June .

That being said, I’m not gone yet. Despite a return to my final year of software development in school, I’ll continue to chip in to the efforts of the QA team and other projects to come, only I’ll be on IRC at a slightly different time of day.
Thanks Mozilla and in particular the friendly folks of QA for the first-rate experience!
Take care Mozilla,
Aaron






August 25, 2009 12:24 AM
August 24, 2009
One of the most frustrating thing for users is to have Firefox crash on them. As we’ve discussed before, we’ve been writing a series of articles to document the top crashes and get them searchable by crash signature.
Just documenting the top 50 crash signatures will greatly improve the experience of users coming to SUMO. It will also help give us somewhere to point users to from the forums or live chat. Towards that end, we’ll be having a one-day sprint to write these articles and get them into the knowledge base and we could use your help!
On September 3rd, we’re going to get together to write as many of these crash articles as we can. We’ll have members from Mozilla’s QA team as well as platform and branch development teams on hand over IRC to help with understanding crash bugs or stacks and answer any questions you may have about the crashes. We’ll be tracking our progress on this page.
We look forward to seeing you there!
August 24, 2009 11:22 PM
The designers of the iPhone had an immense amount of courage. They finally removed the scrollbar, a persistent and harmful UI anachronism. Given the amount of time spent scrolling on computers, requiring the move from your locus of attention to the small target that scrollbars represents has wasted immense amounts of time. If you calculate it out conservatively, the scrollbar widget wastes almost one complete day a year. And that’s only if you scroll once every 6 minutes. Multiply that by number of the 300 million Firefox users and you’d find that the scrollbar wastes over three-fourths of a million man-years of web browser’s time. Every year.
No wonder we have scroll wheels and two-finger scrolling. They remove the 4 seconds of back-and-forth targeting the scrollbar. They save the world millions of man-years of wasted time.
Fennec (Firefox Mobile) and the iPhone go the next step and get rid of the scrollbar all together. There just isn’t enough room on those little screens. They both use pan-to-scroll, which solves the problem with the exception that getting around on pages so over-flowing with length that they stretch for half an infinity (like the Line of succession to the British throne) takes half of forever. The problem is so horrific that mobile Safari had to implement a band-aid UI patch for jumping back to the top of a page.
There has to be a better way of solving the problem, one where you get the immediacy of touch-and-drag to pan but where you also don’t get stuck scrolling the scenic route.
Here are two thoughts on how to solve the problem.
Sticky Scroll Indicator
The obvious solution. When you start to scroll, the scroll indicator fades in. After you stop scrolling, the scroll indicator remains and can be interacted with for some amount of time. Time based solutions are always a tricky — the timeout is never the right length for everyone — but this one seems pretty pit-fall free. The scrollbar is there when you need it and gone when you don’t.
Scroll-to-zoom
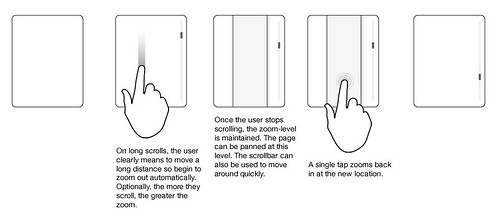
The more visually impressive solution, although I’m not convinced it is better than the obvious solution. During long scrolls, the page automatically zooms out. Optionally, the longer the scroll, the further the zoom. The zoomed out page can be panned, and the now-present scrollbar can be used for quickly jumping around. A single tap zooms you back in. This gives you a wonderful visual table-of-contents map of the page you are moving about, but at the potential cost of simplicity.
Other solutions
Are there other solutions?
August 24, 2009 10:58 PM
 Last week’s Add-ons Meetup in New York City turned out to be really great. The attendees ranged from the “curious about add-ons” to developers & companies that are hard-core add-on developers. It was a perfect blend of participants and it allowed us to be extremely flexible in how & what information was presented.
Last week’s Add-ons Meetup in New York City turned out to be really great. The attendees ranged from the “curious about add-ons” to developers & companies that are hard-core add-on developers. It was a perfect blend of participants and it allowed us to be extremely flexible in how & what information was presented.
While we had a set agenda for the event, we kept the event very loose encouraging participation at any point. We wanted attendees to be able to get immediate feedback and feel engaged and from the level of interaction, that was definitely the right choice (Thanks Fraser!). We also made sure to have food & drink for attendees as a full belly always helps keep developers focused.
 Mozilla’s Justin Scott gave excellent overviews of Developer.AMO & Collections and fielded a number of questions about these two initiatives. Developer.AMO was a hot topic since we were actively looking for greater detail on what information is important to developers. The consensus was that more metrics is a good thing & providing greater detail in terms of data or mechanisms that could help developers better gauge conversions would greatly help in managing their add-ons. Justin also discussed opening up multiple release channels for add-ons that would allow developers to support multiple versions of an add-on in a single listing.
Mozilla’s Justin Scott gave excellent overviews of Developer.AMO & Collections and fielded a number of questions about these two initiatives. Developer.AMO was a hot topic since we were actively looking for greater detail on what information is important to developers. The consensus was that more metrics is a good thing & providing greater detail in terms of data or mechanisms that could help developers better gauge conversions would greatly help in managing their add-ons. Justin also discussed opening up multiple release channels for add-ons that would allow developers to support multiple versions of an add-on in a single listing.
 Rey Bango followed, presenting on the recent Contributions project which allows developers to request financial support for their project. More than one developer expressed a strong desire to have a “subscription-based” contribution mechanism added to Contributions essentially providing a mechanism for “pay-as-you-go” type of services. Also, along the lines of other marketplaces, there was a suggestion of being allowed to offer a free and a premium version of an add-on. The multiple release channels mentioned above could be a way of making this happen.
Rey Bango followed, presenting on the recent Contributions project which allows developers to request financial support for their project. More than one developer expressed a strong desire to have a “subscription-based” contribution mechanism added to Contributions essentially providing a mechanism for “pay-as-you-go” type of services. Also, along the lines of other marketplaces, there was a suggestion of being allowed to offer a free and a premium version of an add-on. The multiple release channels mentioned above could be a way of making this happen.
 Last but not least, Shaun Salzberg of Drop.io gave an excellent demo of the Drop.io add-on and service. The Drop.io add-on is really one of those extensions that pushes the limits of JavaScript and it was exciting to see what this team had done. It was especially important to show those developers who are just getting their feet wet in the Mozilla platform the power available to them.
Last but not least, Shaun Salzberg of Drop.io gave an excellent demo of the Drop.io add-on and service. The Drop.io add-on is really one of those extensions that pushes the limits of JavaScript and it was exciting to see what this team had done. It was especially important to show those developers who are just getting their feet wet in the Mozilla platform the power available to them.
We’d like to thank the team at AdaptiveBlue for their help. Apart from providing the venue, they helped to spread the word locally and generate plenty of buzz in the add-on community.
Our next meetup will be in Miami, FL on September 15th. If you’re in the area, please be sure to stop by. Entry is free and we’d love to get your feedback.
ShareThis
August 24, 2009 07:55 PM

There are some things in life you need to learn … such as learning to walk, to read and knowing that pie is ‘off’ in your fridge (though all of that is hopefully instinctive)
And there are also some things in life in worth learning well … such as speaking French, having patience, and making great brownies!
Then there are those things in life which by learning, you just know are going to make your life a whole lot better! Learning about Firefox is one of those, and for the last few weeks, we’ve been working on a new fun learning destination for Firefox – called the “School of Firefox”. We’ll soon be able to take you through lessons, tips and videos on all you need to know about using Firefox.
Its going to help new Firefox users get set up and familiar with Firefox features fast, and for those of us who think we already know the deal, we hope there’s lots more besides to learn about your fox!
We’ll be sharing more about the site in the next couple of weeks. So get your pencil’s pencils sharpened – a new fun way to learn Firefox is coming soon!






August 24, 2009 07:29 PM
After a brief hiatus, we are back again for another edition of Labs Night, our monthly meetup to discuss Labs projects, your projects and the Open Web. Our August session will be this Thursday, 8/27 6-9 pm at the (still) new Mozilla HQ – 650 Castro Street, Suite 300 in downtown Mountain View. The event is open to everyone, so if you are in the area feel free to stop by.
Our featured speaker this week is Li Gong, Chairman and CEO of Mozilla Online, the Beijing based subsidiary of the Mozilla Corporation. Li will be talking about a wide variety of topics related to firefox, the mozilla community and the open web in China.
We will also hear what a lot of the Mozilla Labs projects have been working on, in 5 minute lightning talk style presentations. We’ll have a few slots open for other lightning talks as well, so if you are working on a cool project, this is a great opportunity to show and tell.
And if that’s not enough, we’ll also be providing pizza. Please RSVP by commenting on this blog if you plan to attend. Hope to see you there!
PS: We may have another super exciting speaker this week. We will post an update once we hear confirmation.
August 24, 2009 07:11 PM
Sumo
Knowledge Base
- Attn: bug 505356 “Open all external links in KB articles in new window/tab” -Milos
- Annoying when you read a support article, and you want to read a .. right-click
- Bookmarks reorganization — Bo is going to start filing bugs this week for new task-specific articles.
- Thanks to Bo, all top 5+ crash articles are in the KB. One new one this week. Big thanks to Bo!
- cilias to test searches to make sure they work (including non-en-US locales)
- cww to see how we can add “crash” to the Crash Report form as an OR search, to ensure that the generic “Firefox Crashes” article is always included in the results
- This week we’ll focus on getting the Bookmarks and Cookies articles split.
- KB CSAT took a dive in March, but I don’t know the cause
- There were three firedrills in April, which was the second month of drop, but that doesn’t explain March
- djst to ask Patrick and Ken about this to see if there are other similar drops in March-April other than SUMO CSAT
- PRD draft for KB article requests, tracking, and discussion. (Discussion thread)
- Looking for feedback from localizers: Simplifying how to translate articles.
- Probable change in screencast/screenshot policy. Have a look. Give your feedback. [1]
- Sumodev stuff for anyone who wants to test on support-stage:
- Email notification when an edit is made/approved/rejected (with comments). bug 446082
- Reviewers now set “Mark other translations as out of date” instead of editors. bug 469188
Forum
- Writing guidelines for forum moderators (draft)
- Forum search currently filters by locale, which is rather pointless since we only have one locale and it wouldn’t be able to distinguish other languages even if someone e.g. wrote a post in German
Live Chat
- Top tags from last week
- Crash was the top issue all of last week
- Web client demo – currently in testing
- Goal is to have Milestone 1 complete this week
- zzxc to make sure the page works and then SUMO team will test. Then we can get more testing from Live Chat people once we know it at least work relatively well.
- Canned responses have been updated with new common issues and troubleshooting steps
Roundtable
- SFD will be a KB writing sprint on 9/3
- Blog post about it to be posted today
- Laura wants to know if we should link to SUMO articles on the Plugin Checkup page.
- Let’s definitely link to SUMO, but let’s make sure to review the target articles to make sure they’re up to date.
August 24, 2009 05:53 PM
Three years ago this coming December I went to Amsterdam and installed our first non-US data center location.
I remember coming back and was up late at night (fighting jetlag) setting up the Netscaler load balancers. By early January we had a CVS mirror up and running and a week later had staged www.mozilla.com and www.mozilla.org in Amsterdam. By the middle of February we had shifted European production traffic over to Amsterdam.
By May of 2007 (oh and here) we started serving addons.mozilla.org out of Amsterdam too.
Since then, the San Jose data center has grown from seven racks to twenty-four and nearly 500 servers (for the sake of this post I’m counting the 150 Mac Minis as “servers”).
Unfortunately, Amsterdam hasn’t seen the same sort of server growth and in the past half year or so we’ve had to pull sites back from Amsterdam and serve them from San Jose only. When the load balancers there could no longer handle the SSL traffic in January we stopped serving addons.mozilla.org out of Amsterdam too.
The Reboot
On September 2, we’ll reboot Amsterdam. Much like The Six Million Dollar Man, “… we can rebuild [it]. We have the technology… We can make [it] better than [it] was before. Better, stronger, faster.”
This morning we shipped a half loaded HP c7000 BladeSystems chassis out to Amsterdam. Next week both Arzhel and Derek will be in Amsterdam to deploy new servers and turn down some of the old legacy hardware.

One of the issues with the current Amsterdam deployment is that we can only really serve static sites – sites that don’t have a database behind them. It’s a bit more complicated to replicate databases to remote locations and keep them in sync with San Jose.
Based on our success with the Zeus ZXTM platform, we’re deploying a Nehalem based ZXTM cluster. Much like we originally did with addons.mozilla.org, we’ll have a platform where we can proxy/cache any Mozilla website and serve it out of Amsterdam.
We’ll also be deploying a new global load balancing system that Arzhel’s spent time staging and getting ready for production.
The Plan
During tomorrow night’s downtime window we’ll start the process of temporarily shutting down Amsterdam. We’ll pull back all websites to San Jose and stop serving web content out of Amsterdam for about two weeks.
We’re doing this in advance of the actual deployment to make sure we don’t hit any surprises.
What won’t be affected?
There are two VMware ESX servers in Amsterdam that we won’t be touching. A quick list of hosts that won’t be affected by this are:
- dn-vcs01
- gravel
- geodns02
- l10n-01
- rhino01
- sea-qm-centos5-01
- sea-qm-win2k3-01
- konigsberg
I’m excited about this. I’ve said before I’m still a network guy at heart and I really like getting content closer to consumers. I’m hoping this Reboot becomes an easily deployable platform for other parts of the globe.
August 24, 2009 04:09 PM
When we left off, we showed that the #1 reason why people refused the Firefox Major Update offer was their frustration/preference/confusion related to the awesome bar (or location bar). There are a few things interesting with this piece of feedback and with all the feedback more generally:
- Virtually everyone who provided feedback had previously used Fx3 and subsequently reverted back to Fx2. This was 100% descriptive of this cohort and largely described all other users who were kind enough to share their thoughts.
- Some of the issues cited have since been resolved (since last summer). Clearly, many users tried Fx3 when it was initially released, then reverted back to Fx2 shortly thereafter, and now they still won’t consider upgrading because of their initial experience (even if that initial issue has since been resolved). You never get a second chance to make a first impression!
Returning to our cohort of users not fully satisfied with or fully comfortable with the awesome bar, we’ve released a series of enhancements in Fx3.5 that should resolve their concerns. Alex Faaborg provided an extensive walk-through, and here’s one key section that should help this group of users:
Ability to Control What Appears in the Location Bar Search Results (Proactive Privacy)
When we expanded the capabilities of the location bar to search against all history and bookmarks in Firefox 3, a lot of people contacted us to say that they had certain bookmarks they didn’t really want to have displayed. In some cases users had intentionally hidden these bookmarks in deep hierarchies of folders, somewhat similar to how one might hide a physical object. Having something from your previous browsing displayed to someone else who is using your computer (or even worse) to a large audience of people as you are giving a presentation, is really one of the most embarrassing things that Firefox can do to you. So now in Firefox 3.5, users have complete control over what types of information are displayed in the location bar (or suggestions can be turned off entirely):

So, what actions items can come of this user feedback?
If we think this concern surrounding the location bar is solely limited to existing Fx2 users, we could consider some special messaging for them. However, I would venture to guess that some small fraction of the Firefox user base currently on either Fx3 or Fx3.5 (93% of all users) share similar thoughts about the location bar. If so, then it would likely be worthwhile for us consider a couple options:
• Modify Firefox itself.
Below is a simplified mock-up of just one idea I came up with (please note that I don’t know anything about UI). I’m not sure if the average user knows about Tools->Options, so the concept here is that a person could easily understand how the location bar works and adjust it (according to their preferences) within a fraction of a second.

• Up-level messaging about the location bar and its latest enhancements.
Utilizing key touch points, such as the firstrun page, whatsnew page, or firefox.com page, could help users feel more comfortable with the location bar and its awesome functionality. For example, is it more important for us to be using these critical touch points to promote open video formats and Fx add-ons, or to highlight Firefox’s most utilized feature and how it can best help a user in his/her everyday life (and not frustrate them)? At the very least, this seems like a question we should be asking.
What are your thoughts?
August 24, 2009 03:34 PM
As many people already know, SUMO as a support web platform is built around open source software. For the knowledge base and forum, we use TikiWiki, an open-source PHP-based content management system. What fewer people might know is that SUMO is currently based on TikiWiki 1.10, which is almost two years old today. The latest version of TikiWiki is 3.1 and in only a couple of months 4.0 will be released.
This week, TikiWiki community lead/member Marc Laporte is paying me a quick visit in Eskilstuna, Sweden to discuss our current situation and to figure out what to do with SUMO. We have identified three potential plans:
- Plan A: upgrade SUMO to TikiWiki 4.x. This is what I’m hoping we’ll be able to achieve. The question is how much work it means to get to 4.x and how much better things will be once we’re there.
- Plan B: fork our current codebase and continue to add our own features on top of it. This is essentially what we’re doing today, and it’s not exactly ideal since we end up doing work in parallel with TikiWiki, and we’re wasting precious resources.
- Plan C: migrade our content to another CMS, e.g. Drupal. By far the most costly effort in the short term, and not clear whether the benefits outweighs the investment cost.
Now that Marc and I have the opportunity to spend two full days working face to face, I’m hopeful that we can not only pick Plan A, but come up with a solid plan for the first few steps to make the plan a reality.
If you’re part of the SUMO or TikiWiki community, I would love to hear what you think and if you think there are things we should focus on discussing!
August 24, 2009 03:07 PM
I really want to help .orgs tap the power of the open web during Mozilla Service Week. The challenge: finding a fun and helpful task I can take on in just a few hours that also fits my skill set. I didn’t find a perfect match in the Idealist volunteer database, so I’ve decided to roll my own Service Week activity: a 2 hour Creative Commons licensing clinic, plus a screening of RIP: A Remix Manifesto.

My thinking process was simple: I asked ‘what have my .org friends asked me to help w/ in the past year?’ and ‘what questions have been most fun to answer?’. I quickly zoomed into the topic of open content, licensing and business models. Many non-profits want to get their content out there in the open, but they just don’t know how. I figured I could make the world — and the web — better by volunteering to help with this for a few hours.
The specific plan is to offer open content advice and inspiration to the 150 .orgs and social entrepreneurs at Toronto’s Centre for Social Innovation. I will start with a lunch time screening of RIP: A Remix Manifesto (the inspiration part). Then I will run a Lucy-Van-Pelt-esque Creative Commons info booth in the lunch area for a couple of hours (the advice part). Four hours of my time. Simple to organize. Likely very fun.
A challenge to other Mozillians (and everyone else): if you can’t find a Service Week opportunity that compels, roll your own. In particular, I’d encourage:
- … my MozYYZ colleagues to join at the Centre for Social Innovation to offer advice on the topic of their choice. Imagine an ad hoc open web advice fair!
- … my compadres at Creative Commons to set up their own open content coaching sessions during service week (the open web isn’t just about tech, eh).
- … Mozillians everywhere to leverage non-profit coworking spaces as a way to help many non-profits at once (I can suggest contacts in cities like Paris and Sao Paulo).
If you want to pitch in with the Toronto clinic or plan to take up my challenge, please post a comment below. And, of course, also sign up on the Mozilla Service Week site. Fun. A better world. And a better web. That’s what’s ahead for Service Week!
Posted in mozilla, serviceweek






August 24, 2009 02:21 PM
Sofia DevGarage is a Mozilla Add-ons Workshop organized by the
community.
Sofia DevGarage will be the first development garage in Sofia. If you want
to learn more about the following topics:
* What is the architecture of Mozilla Firefox and Mozilla Thunderbird;
* How and why to start writing extensions for Firefox and Thunderbird;
* and to write your first add-on during the event
More details: english, bulgarian.
August 24, 2009 10:36 AM
More than one month has gone by without a status update. Obviously it's vacation time :-)) We're hard at work to finally get our next release out of the door for Lightning and Sunbird. More on that in a separate post. Over the last six weeks we have fixed 22 bugs, which are listed below.
- 328216: It is not possible to assign duration to a task
- 378951: [Mac] non-functional button in About Sunbird dialog
- 411849: Default date for add New Task is current day rather than the selected day
- 430090: Collapsed state of Today pane is not remembered when dragging the splitter
- 445304: Today-pane: width should be set mode-dependently
- 459381: Calendar and task tabs should be persistent
- 471860: Use .trim*() in Calendar
- 483643: Strict JavaScript warnings "reference to undefined property"
- 500718: (scalability) useless refresh of unchanged calendars in onCalendarAdded/-Removed
- 501402: Day View not updated correctly after deleting multiple events
- 501613: Croatia holidays
- 506461: Change the menupopup id in messenger-overlay-toolbar.xul
- 506608: View, task list, and toolbar broken after startup
- 507105: Task list doesn't update correctly when adding/removing calendars
- 507170: Removing calendar breaks unifinder
- 507700: WARNING: Illegal character in window name calendar-properties-dialog
- 508295: Task list: creating new task via double click or context menu entry fails
- 509335: Make use of zoom controls for calendar views
- 509345: US Holidays file uses inconsistent categories
- 509405: Calendar builder tinderboxen down? starting 2009-08-10
- 509936: Warning: undeclared variable in minimonth.xml
- 510499: Correcting grammar on Sunbird homepage
As always, our thanks go to all developers, contributors, localizers, testers, and supporters that have made this possible.
August 24, 2009 09:51 AM
On the afternoon of Sunday 09Aug2009, our colo overheated and shutdown. The gory details are here, but basically when the air conditioners failed, the room quickly overheated to unsafe levels, and machines took themselves offline before they were physically damaged. All our build/unittest/talos infrastructure, along with large portions of the rest of Mozilla infrastructure, came to an abrupt halt.
Matthew (mrz) phoned me soon after the colo went offline, just to give me a heads up, so I was able to forewarn others in the group. The rough timeline was:
- 13:30 PDT Sunday afternoon: colo offline
- 21:30 PDT Sunday evening: Mozilla back online
- 01:00 PDT Monday morning: RelEng declares build infrastructure back online
While its bad for a colo provider to have failures like this, it was impressive to watch how the RelEng and IT groups pitched in together to get things going again so quickly - reviving ~420 RelEng machines in under 12 hours was quite a feat.
August 24, 2009 09:15 AM
Doug just posted about the device orientation support he recently landed. Sitting here with my MacBook Pro, I just had to play with it — resulting in this little demo. Orientation + CSS Transforms FTW!
August 24, 2009 08:21 AM
For the next three posts, I’m going to be highlighting three areas of the Firefox user interface that could benefit from animation. Stephen Horlander and myself have been looking at Firefox with an eye towards where movement could make Firefox an easier, more appealing, and perhaps even faster experience with movement.
First, it should be asked why we would add animation Firefox. Animation in the browser is a tool, but not a goal unto itself. Wherever animation is used, it should be with a purpose (not “it looks cool”) and benefit to the user (not “makes user look cool.”)

Like many web technologies, animation is a useful but easily abused tool. The early web and the dawn of the .gif saw animation heinously overused with blinking, spinning, and scrolling animations added to sites because they looked cool.
As the web calmed down a bit and web and interactive design began to develop, designers and developers found that animation could be beneficial to users. For instance, it can make tasks seem more like real-world affordances, and thus easier to visually understand. It could give users feedback on how digital objects were being moved or manipulated. And yes, they could make interactive experiences more visually appealing.
The first area we feel could benefit from animation is the movement of toolbar items within their rows on the Firefox chrome. This includes buttons like Home and Reload, the bookmark bar, and tabs. Currently, these items can all be shifted and reordered, but little visual feedback is given for these tasks. For tabs, only a thin strip shows where a dragged tab will be dropped.

By adding animation to the process of rearranging items, not only will Firefox feel more lightweight and adaptable, but it will be more visually clear what the user is manipulating and how the UI will be changed by letting go. For instance, animations of tabs being manipulated is essentially live preview of tab rearrangement: if a tab is slid to the right and an animation shows it doing so, releasing it only makes permanent what is being shown. This is similar to the tab animation motion currently in Safari and Chrome.

Because tab tearoff and tab rearrangement would utilize similar mouse movement, some thresholds should be added to prevent users from accidentally performing an unintended action. As Shorlander recommended, a “soft snap” could make tabs within a region of the tab bar slide, and falling outside that region causes them to tear off.
Slight animation could also give newly created tabs the feeling of organic growth into the browser.

(more details in the wiki)
The above sketches are based on work by Stephen Horlander.






August 24, 2009 07:42 AM
One of the coolest apps I saw when the iPhone came out was the wooden balance game Labyrinth. You basically tilt your phone to move a ball around the screen, avoiding holes, and trying to get the ball to a goal. It made use of a feature of many modern devices — accelerometers.
Obviously clear that there should be a webapp for doing just that. What was missing was a javascript API.
In recent Mozilla trunk builds, I have added support for an orientation event. This new event will allow you to build applications and listen for changes in orientation. (note, the first platform to support such an event is any MacBook Pro. Others will follow).
Simple Call:
To use this new event, you will add an event listener as you normally would:
window.addEventListener(”MozOrientation”, orientationChange, true);
Your callback will be called, when there is a change in acceleration, passing the current orientation:
function orientationChange(o) {
}
Simple Result:
The passed object has 3 attributes – “x”, “y” and “z”. Each value is between -1 and 1 where zero is the “balance point”. For example, suppose you device is a MacBook Pro and it is sitting on a desk that is perfectly level, you would expect to see:
x = 0
y = 0
z = 1
x is the axis in the direction from the left side of the keyboard to the right side of the keyboard (basically the axis that is along the home row keys) is level. If I lift up the left side of the keyboard, x will increase. if I lift up the right side, x will decrease.
y is the axis in the direction from the front of the laptop (where the mouse is) to the back of the laptop. If I lift up the front of the laptop (the side closest to me), y will decrease. If I left the back towards the front, y will increase.
Got that? Yeah, physics is pretty hard. 
x and y can easily be visualized. If you have a recent trunk build for the Mac, try loading this demo page:
http://people.mozilla.org/~dougt/ball.html
z basically will tell you that the laptop is sitting right side up. if z was -1, you would know that the laptop (probably closed) and is sitting on its screen. Of course the value will change as you rotate the laptop / device in this direction.
Right now, there is only support for the Macbook Pro. It is pretty easy to add support for different OSs. We have code for Samsung Windows Mobile devices, and for the HTC Windows Mobile devices. We still need support for linux and for Windows. If you are interested in adding support file a bug and start looking at http://mxr.mozilla.org/mozilla-central/source/widget/public/nsIAccelerometer.idl
The API isn’t fixed and may change. I do invite you to comment. Keep in mind that we want a really simple and straight forward API to expose orientation events to web developers. If your response has either “RDF” or “DCCI” in it, please reread the last sentence. 
Thanks again and hope you enjoy.
August 24, 2009 03:24 AM
Feature Description
We want Firefox to override server-supplied 404 error pages in certain cases. The Firefox 404 page should provide the user with tools we think are more useful to the user for resolving the situation, than the server supplied page. This includes alternate ("did you mean") URLs derived from the Places database and some pre-loaded search links/controls.
Status
The newest patch is almost ready for review.
This patch is mostly focused on making the code right, but there are a couple of functional changes:
- The Firefox 404 error page is now pref-controlled. There's a pref to turn it on and off, and a pref to limit which server-supplied 404 pages we'll override. Currently we will only override server 404 pages of 512 bytes or less.
- We're dropping the background image for now.
Next Steps
- Complete the patch and get it in for review.
- Blog about it.
Notes
- This feature is being tracked by Bug 482874 - Provide a friendlier/more useful alternative when the user encounters a 404 error page.
Edit: Added Notes section.
Permalink
| Leave a comment »
August 24, 2009 02:28 AM
August 23, 2009
Introduction
I recently have begun giving serious thought to what command chaining might look like in Ubiquity and the various considerations which must be made to make it happen. The “command chaining,” or “piping,” described here always involves (at least) two verbs acting sequentially on a passed target—that is, the first command performs some action or lookup and the second command acts on the first command’s output.
A few days ago I penned some initial technical considerations regarding command chaining. In this post I’ll be point out some linguistic considerations involved in supporting a natural syntax for chaining.
Simple syntaxes: sequential vs embedding strategies
When it comes to creating a natural language interface, there’s always a decision to make between requiring a certain kind of input, or working a little harder to understand the user’s natural input. From an implementation point of view, adopting certain programmatic conventions is of course simpler and to this end, there have been a couple different “unnatural” command chaining syntaxes suggested. While these both go against Ubiquity’s basic tenet of natural syntax — that is, to not introduce rules which contradict the user’s natural language — which gives Ubiquity its strengths of usability and memorability, I’ll entertain them here as they illustrate two different structural relationships that we will want to consider.

The first suggestion is to adopt the shell pipe (|), which would lead to input such as
1
| translate hello to Spanish | email to Jono |
While this itself is pretty unnatural unless you speak shell, note that this syntax is similar to the more natural “, and” syntax, yielding translate hello to Spanish, and email to Jono, which we will consider below. I’ll refer to this strategy as the sequential strategy.
Another very interesting proposal by Alex Fritze is to embed each subordinate computation into an argument position, marked by parentheses. This could also be parsed relatively straightforwardly by writing a noun type which first checks for parentheses and then runs the content of the argument through another ParseQuery.
2
| email (translate hello to Spanish) to Jono |
I’ll refer to this pattern as the embedding strategy.
Sequential and embedding strategies in natural language
What’s interesting about the two proposals above is that both strategies are seen in natural language. The sequential strategy could correspond to the following linguistic phenomena:
- coordination: a non-hierarchical joining of two or more clauses, often marked by a conjunction. Here’s an example from English:
- “[I made a sandwich] and [you will eat it]” where [] represent clause boundaries. Here, “and” is the conjunction.
- serial verb and converb constructions: a joining of multiple verbs or verb phrases within a single clause, with shared subject and tense/aspect values, with no particular conjugation or delimiter between them. Such constructions are common in many African and east Asian languages. Here are two examples:1
- A converbal construction in Japanese:
3
4
5
| 僕は サンドイッチを 作って 食べる
boku-wa sandiʔchi-o tsuku-ʔte tabe-ru
I-TOP sandwich-ACC make-CON eat |
“I (will) make a sandwich and eat [it].” (Here, `TOP` = topic, `ACC` = accusative, `CON` = converbal ending)[^3]
- A serial verb construction in Mandarin Chinese:
6
7
8
| 我 作 三明治 吃
wǒ zùo sānmíngzhì chī
I make sandwich eat |
“I (will) make a sandwich and eat [it]” or “I (will) make a sandwich [in order to] eat [it].”
Note that in both the converb and serial verb construction, the second verb (eat) takes shares its object (sandwich) with the first verb and there is no need for a pronoun such as “it” to introduce that argument as it is with coordination, above.2
The embedding strategy is observed in natural language as well, in the form of the following phenomena:
- embedded clauses: a sentence is itself the argument of another verb. Example:
- “John says [he likes sandwiches].”
Embedded clauses, however, clearly have no relation to command chaining and does not require our attention.
2. relative clauses: a partial sentence3 is attached to a noun in order to describe it or distinguish it from other possible referents. Example:
- “You ate the sandwich that I made” where “sandwich” is called the “head” of the relative clause, and “I made” is what I here call the “partial sentence” (see footnote). The “relative clause” is used here to distinguish “the sandwich that I made” from other sandwiches.
The natural syntax of chaining
So which strategy is used in complex natural language commands: the sequential strategy or the embedding strategy? Both the sequential strategy and embedding strategy can be involved with commands:
9
10
| [Make a sandwich] and [eat it]!
Eat (the sandwich that I made)! |
These two commands do not mean the same thing, though, and only (9) is the kind of command we would want to give Ubiquity. The problem with relative clauses, as in (10), is that it presupposes the existence of the sandwich in the context. If we both know you just made a sandwich, saying (10) is perfectly appropriate, but out of the blue it doesn’t make sense. For this reason, only the sequential strategy is used in the natural syntax of chaining.
Parsing the sequential strategy
In natural language, unlike the initial simple proposals laid out above, there is often no clear delimiter marking the boundary between the two parts in a sequential relation (e.g. examples (3) and (6) above, particularly given that neither Japanese and Chinese normally break words with spaces). How would we parse a sequential string of commands?
Let’s assume for our purposes here that we can identify find all verbs within the input string.4 Parsing a sequential strategy string is not particularly difficult if we can also assume that the verb in any particular language is either always verb-initial or always verb-final. Let’s look at both cases:
- Always verb-initial: Mandarin Chinese:
11
12
13
| 翻譯 hello 到 西班牙語 送 給 Juanito
fānyì hello dào xībānyáyǔ sòng gěi Juanito
translate hello to Spanish send to Juanito |
“Translate hello to Spanish [and] send [it] to Juanito”
1. find every possible verb:
翻譯hello到西班牙語送給Juanito
2. as every verb marks the beginning of a sentence, we now have our two commands: “翻譯hello到西班牙語” (translate hello to Spanish) and “送給Juanito” (send to Juanito).
* Always verb-final: Japanese
14
15
16
| helloを スペイン語に 訳して Juanitoに 送って
hello-o supeingo-ni yakus-ite Juanito-ni oku-ʔte
hello-ACC Spanish-DAT translate-CON Juanito-DAT send-CON |
“Translate hello to Spanish [and] send [it] to Juanito”
1. find every possible verb:
helloをスペイン語に訳してJuanitoに送って
2. as every verb marks the end of a sentence, we now have our two commands: “helloをスペイン語に訳して” (translate hello to Spanish) and “Juanitoに送って” (send to Juanito).
For languages where there is a clear conjunction between the two commands, such as English “and”, we can also use that conjunction as a delimiter as well. We then simply execute the first command and then execute the second with the first command’s output in its interpolation context. This way the output of the first command will be picked up both by an overt pronoun such as “it” in the second command and without it, such as in the Chinese and Japanese examples above.5
The only potential problem with this approach is in the case of languages where some commands are verb-initial while others are verb-final. I note that such languages do exist in a previous blog post, Where’s The Verb. In these languages, commands can be expressed by more than one verb form (such as infinitive, imperative, subjunctive, etc.) and some of those verb forms are sentence-initial while others are sentence-final. Here’s one such example from German:
“search hello with google” (German)
1. Infinitive: hello mit google suchen
2. Imperative: suche hello mit google
Here the verb for “search” is “suchen” (infinitive) or “suche” (imperative). I know that this same type of phenomena occurs in other Germanic languages such as Dutch with infinitive and imperative and also other languages such as Modern Greek with infinitive and subjunctive forms. If you are a speaker of one of these lanuages (German, Dutch, Greek, etc.) I would love to know whether you can chain verb-final and verb-initial commands together.
Conclusion
In this blog post I examined command chaining in natural language, focusing on data from English, Mandarin Chinese, and Japanese, which exhibit three linguistically different approaches to chaining. What we found is that the sequential strategy—that of listing the commands one by one, in order of execution—is what is used in natural languages, rather than any sort of embedding. This fact, combined with the fact that our parser can recognize every available verb, offers a simple approach to doing a naive parse of natural command chains in most languages, even without explicit delimiters.
In a final installation of this series on “exploring command chaining,” I hope to consider how the Ubiquity interface itself could present command chains and aid in its input.
Related Posts
- Exploring Command Chaining in Ubiquity: Part 1
- Command Chaining with Oni?
- Count command for Ubiquity
Related posts brought to you by Yet Another Related Posts Plugin.
August 23, 2009 11:14 PM
A side effect of enabling the l10n updates is that en-US nightly builds that finish after 7AM PDT (which is when l10n nightly repackages are triggered) will take longer to receive an update offer. Specifically, this happens mainly for win32 builds since they take way longer to finish.
Currently there is only one machine that checks for pending updates to be generated and it generates them all pending jobs in one shot, pushes the snippets live and then checks again for more pending jobs.
The problem is that if the system picks X number of pending updates it will process them one by one but without pushing any snippets and partial MAR files live until it finishes with all X jobs.
Therefore, since the en-US nightly for win32 finishes after 7AM, it falls in the bucket of pending jobs and it can take two or three hours before the snippets are pushed live.
To fix this regression we have decided to have a temporary fix to our update generation system until we do the long term infrastructure changes.
To follow the work on this fix please follow the work on
bug 511901.
We are really sorry for any inconvenience and we would like to have it fixed as soon as possible.

This work by
Zambrano Gasparnian, Armen is licensed under a
Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License.
August 23, 2009 03:54 AM
August 22, 2009
In the previous two sections of my guide, I discussed
basics of functions and then went into
the specifics of types and names, as represented by the Elsa AST nodes. In this section, I will cover classes and some more errata on declarations. As I have mentioned earlier, the subsections of this third step will be visited out of the order of their numbering.
What has been covered so far:
Step 1: Building and running your tool
Step 1.1: Running the patcher
Step 2: Using the patcher
Step 3: The structure of the Elsa AST
Step 3.1: Declarations and other top-level-esque fun
Step 3.1.3: Function
Step 3.1.5: Declaration
Step 3.1.6: TypeSpecifier
Step 3.1.8: Enumerator
Step 3.1.11: Declarator
Step 3.1.12: IDeclarator
Step 3.4: The AST objects that aren't classes
Step 3.4.4: CVFlags
Step 3.4.5: DeclFlags
Step 3.4.8: PQName
Step 3.4.9: SimpleTypeId
Step 3.4.11: TypeIntr
Step 3.1.9: MemberList (inside a class)
MemberList has only a single variable:
ASTList<Member> list.
Step 3.1.10: Member (part of a class)
Member nodes represent a member of a class type. Like other nodes, this is mostly represented by its subclasses,
MR_decl,
MR_func,
MR_access,
MR_usingDecl, and
MR_template. The node itself has two members,
SourceLoc loc and
SourceLoc endloc. End locations represent the location just after the semicolon or closing brace, such that the range of text matches
[loc, endloc); if you recall, this is the same syntax that the patcher uses when working with ranges of location.
Each of the subclasses of Member only adds one variable, which is the type that member represents. MR_decl adds Declaration d, hence it is used for all declarations within the class, be it a variable declaration like int x, a type definition, or a function without a body. MR_func adds Function f, so it represents all functions that have their body in the class declaration (A(); is a declaration, but A() {} is a function). MR_usingDecl has as its member ND_usingDecl decl (which is covered under the section NamespaceDecl), and MR_template uses TemplateDeclaration d.
The final subclass of Member is MR_access, which has its member AccessKeyword k. This node represents all of the declarations like private:. Since the information keeping track of the access is stuffed in separate AST nodes, you may be wondering how to retrieve this information given only a specific member. The answer, naturally, lies in the auxiliary classes to the AST, something which I have avoided mentioning. Some nodes provide access to a Variable member, one of whose methods retrieves the access to the member. More information about this will be discussed when I talk about that class in detail.
A final thing to note is that Elsa will add some nodes into the AST by the time you use the visitor. These are the implicit methods dictated by the C++ standard. You can check if one of these members is implicit if the DeclFlags variable contains DF_IMPLICIT. Another flag that will also be set is the DF_MEMBER flag.
Step 3.1.7: BaseClassSpec (extending classes)
BaseClassSpec nodes represent a superclass for a class. It has three variables,
bool isVirtual,
AccessKeyword access, and
PQName name, all of which are self-explanatory.
Step 3.4.1: AccessKeyword (controlling access)
AccessKeyword is an enumerated type with three important members. These are
AK_PUBLIC,
AK_PROTECTED, and
AK_PRIVATE, all of which represent what you think they represent. There is also a
AK_UNSPECIFIED member, but that should not be present by the time you get to the AST nodes. Naturally, there is also a
const char *toString(AccessKeyword) method for converting these types into a string.
Step 3.4.7: OperatorName (operator overloading)
These nodes are informational nodes about operators. You should only find them within the
PQ_operator type. The class
OperatorName only has a single method
const char *getOperatorName(). This is the basis for the
PQ_operator name strings, so its results are as mentioned there.
The first subclass, ON_newDel, represents the memory operator overloads. It has two members, bool isNew and bool isArray. The first differentiates between operator new and operator delete, the latter differentiation between operator new and operator new[].
The second subclass, ON_operator, represents the standard operator overloads. It has only one member, OverloadableOp op, which represents the operator being overloaded. The names in the OverloadableOp enum all begin with OP_ and can be idiosyncratic. Example operators are OP_NOT, OP_BITNOT, OP_PLUSPLUS, OP_STAR, OP_AMPERSAND, OP_DIV, OP_LSHIFT, OP_ASSIGN, OP_MULTEQ, OP_GREATEREQ, OP_AND, OP_ARROW_STAR, OP_BRACKETS, and OP_PARENS. There are naturally more, but the other names should be derivable from this sample (pretty much all the idiosyncracies were added to the list); the full list is in cc_flags.h if you need to see it. There is also the standard toString(OverloadableOp) method if you are confused about a particular operator.
Note that some of the operators can be used in different ways. For example, OP_STAR both represents the multiplication operator and the pointer dereference operator. The way to differentiate between the two is via the number of arguments, although one must keep in mind that operators that are class members have one less argument. The postfix increment and decrement operators are differentiated from the prefix forms in that the postfix forms add a second int argument, which is incidentally always 0 if you don't explicitly call the function.
The final subclass is the type conversion operator, ON_conversion. This contains a single member, ASTTypeId type. The member type will have a terminal D_name in its declaration with a null name; the main purpose of the declaration under the ASTTypeId is to capture the pointers.
Step 3.4.2: ASTTypeId (a less powerful version of Declaration)
ASTTypeId is modelled after the
Declaration node, but it's used in places where multiple declarations are not usable. Indeed, its most common usage is to represent a type (nominally
TypeSpecifier) that can have pointers or references. It has two members,
TypeSpecifier spec and
Declarator decl, both of which act as their analogues in
Declaration.
Step 3.1.4: MemberInit (simple constructors)
When working with constructors, the initialization of members is treated separately from the rest of the constructor. In Elsa, the nodes where this happens are the
MemberInit nodes. These nodes contain a few members:
- SourceLoc loc
- SourceLoc endloc
- PQName *name
- FakeList<ArgExpression> *args
The source location and end locations have the standard meanings. The name attribute refers to the name of member being initialized. The arguments refer to the arguments of the function-like calls.
Step 3.1.14: Initializer (the last part of declarations)
The
Initializer nodes represent various ways to initialize an object. The class itself has a single member,
SourceLoc loc, but it has three subclasses, each representing some form of initialization.
IN_expr represents the standard forms of initialization people are used to seeing, something along the lines of int x = 3;. These nodes have a single member in addition, the Expression e member which represents the expression initializing the declaration.
IN_ctor represents the constructor-like initialization forms, such as int x(3);. These have a single member, FakeList<ArgExpression> *args, which represents the arguments within the parentheses.
IN_compound is the final form, which represents the array-like initialization for structs or arrays. For example, int x[1] = { 0 };. This has a single member as well, ASTList<Initializer> inits, which is a list of the initializers within the aggregate syntax. Some words of caution, though, is that aggregate initialization can have unexpected results: multidimensional arrays need not have nested braces, and, in C++0x (and gcc since a long time, though it gives you a warning), you can also omit the braces for nested structures. Bit-fields and statics are omitted from initializers, and, if you have less elements in the initializer than you need, the rest are "value-initialized" (i.e., the equivalent of 0). Elsa, unfortunately, does not aide you any further in deducing which element is actually initialized by any given initializer.
Step 3.1.13: ExceptionSpec (saying what you may throw)
ExceptionSpec nodes correspond to the
throw declarations on function declarations. These nodes only contains one member,
FakeList<ASTTypeId> *types, which represents the types that method is declared to be able to throw.
That is all I have for this part of the pork guide. Part 6 should finish up sections 3.1 and 3.4, so I look track to have part 7 start discussion statements and expressions. I will probably defer the auxilliary API until around part 9 or so, as I really need to play with it some more first.
August 22, 2009 10:44 PM
Jmaher and the Mozilla QA/Mobile Testing Communities showd their mettle this past Friday as this might have been one of the best Testdays we've ever had (past the AMO Preview Testday we had back on May 8th)! I'm not going to say much as the numbers pretty much speak for themselves:
- Toptester: KenS with 51 litmus testcases run
- Top Bugfinder: kbrosnan with 4 bugs filed
- Had a max of 39 in the testday channel at its peak
- Major contributors outside mozQA: kbrosnan, wope, mfinkle, bcombee, fabrice, tmyoung, adric, mekic, Ken, gaby2300
- Verified 196 Resolved Fennec Bugs!
- 24 Bugs Filed with 1 blocker, 2 critical and 4 major bugs in the queue
- 111 Litmus test cases run
Thanks to everyone who participated and see you back in two weeks for another Testday!
-- aakashd
August 22, 2009 08:01 PM
Markus Stange (feed) – Markus works on Firefox native look and feel on Mac OS X and enjoys playing with fancy web technologies.
Josh Geenen moved his blog here (feed)
Mozilla Labs is aggregating blog posts from several blogs here.
August 22, 2009 06:58 PM
Next weekend I am privileged to be attending and speaking at (Keynote, Sunday 30th) the Software Freedom Kosovo Conference in Prishtina. The event aims to bring together local developers and decision making folks with international visitors, to encourage further adoption of Free and Open Source Software in the region. There is a lot of energy to be tapped into in the region, and I am excited to be going.
Speaking of energy, Mozilla community member extraordinairre Besnik Bleta has been working tirelessly on putting together Mozilla Service Week flyers in Albanian to distribute at the event. I received them yesterday and we were panicking with our lack of printing options in the run up. So I mentioned this to Mary Colvig, who came to our rescue and rushed to a local printers to do the job. Thank you Mary! Luckily I have ample room in my luggage to take them back. A few exta kilos is no price to pay for getting the word out in another valuable local community. Local is what matters after all.
If you want to find out more about the event, get in touch. In the meantime, some relevant links to find out more:
August 22, 2009 05:50 PM
Window management has seen relatively little operating sysem level innovation. Tools like ultramon and some graphic card drivers offer support for managing windows across monitors beyond the basic drag-maximize functions. Operating systems tend to focus on contolling the top visible application window, exploiting the hierarchy of apps and windows in different apps. OSX Expose and the 3d stack of Aero support selecting windows, not managing the relationships among them.
With in increasing screen sizes and resolutions, there’s a growing opportunity to capture some of the benefits of multiple monitor layouts within single screens. My BigScreen extension prototype addressed this opportunity by facilitating pushing a Firefox window to the left or right half of the screen and max’ing height.
Turns out Windows 7 has this window left or right side built-in and easily accessible by keyboard. The feature is really useful. In general, I’m finding application and window switching awkward, but it may just be a matter of time. I do love the “peek” feature when hovering on a item in the task bar (pics & video).

In light of this new found affection, I’ve decided to give bigscreen a bit more attention adding keyboard shortcuts emulating Windows 7 in using the arrow keys and have submitted it to addons.mozilla.org /… bigscreen. Windows 7 introduces this functionality in the operating system, with accel-arrow affecting window state.
The latest update to big screen enables, where “accel” is control on Mac and alt on Windows.
- Accel-Left to split to the left
- Accel-Right to split to the right
- Accel-Shift-Left to pull the current tab out and split it to the left
- Accel-Shift-Right to pull the current tab out and split it to the right
- Accel-Shift-Up to split to maximize
If you’re running Windows 7, the only advantage is promoting a tab out of a window and “double-stacking” it, splitting your screeen horizontally between the spawning window and the newly promoted tab.
There’s been some sophisticated work on window management and there’s a real opportunity here for the open web as we learn to make pages work for different screen window sizes. In the mean time, a major caveat: big screen doesn’t play great on dual monitor setups as javascript does not expose separate window sizes effectively (bug 435008 ).
Read more…
August 22, 2009 03:23 PM
Mozilla now has a new WebDevQA Emporer, Stephen Donner! This coronation is meant to be a celebration for the amazing growth in his WebDev QA Kingdom over the past 4 months. He’s gone from a single knight vanquishing bugs at a remarkable pace to bringing in six more valiant helpers in his quest to provide quality across all of Mozilla’s webpages! So, here we are. Let’s all help and bring forth the era of the WebDevQA Emporer!
As with any great Emporer, he needs an equally talented Empress. In this case, there was no one better suited than our very own Samuel Sidler! The service was held on Thursday, August 20, at 3pm. For a video of the event, check out:
http://www.youtube.com/watch?v=XyWnxuOlYVc
I want to thank Raymond “Ray-Ray” Etornam for being the ebb to my flow on this little project, Brandon Sterne for taking video of the coronation and uploading it to Youtube and everyone else involved on getting this done.






August 22, 2009 02:57 AM
Progress
- Enabling PGO for SQLite, mozStorage and Places: Found that the trunk unit test boxes have PGO disabled. I’m leery of checking this in without it being properly tested because these components handle so much user data. Next steps: Lukas Blakk is working on the infrastructure to enable unit-testing of PGO builds.
- JS Component Combining: The combined 60,000 line JS file (!!!) has a problem somewhere in there, causing component registration to fail about 2/3 of the way through. Next steps: Get all the components registering, get numbers on a few platforms to gauge the effect.
- Startup Timeline: No progress. Vlad said it was land-able, earlier in the week. Next steps: Figure out what needs to happen here to finalize and land. David needs to un-rot the instrumentation patch once the timeline lands (rots quickly).
- XPT Linking: Landed! However, really only helps cold startup, which we don’t currently measure. Next steps: Once cold startup testing is available, disable and re-enable to get actual numbers on the effect.
- Static Analysis: No progress, David was out part of the week, and was working on unblocking the dirty profile tests (details below). Next steps: Reduce false positives in the dead-code finder, and run against the full browser context.
- Dirty Profile Testing: Due to a ton of hard work from Alice, dirty profiling of Ts was enabled on mozilla-central! They are the boxes suffixed “dirty” on the tree, currently testing Ts and Ts-shutdown for profiles with small and medium places.sqlite files on all platforms. Data is available for these tests on the graph server – you can see the effect of Vlad’s landing of bug 506470 on startup for a profile with a medium-sized places.sqlite file on this graph. Next steps: get various other dirty profile scenarios detailed, file bugs and get in the pipe. Figure out tree pollution issues.
- Cold-startup Testing: Ts throws out the max value of it’s ten runs, so we don’t have a measurement of how long browser takes to initially startup. Drew, with help from Alice, has started working on the Talos changes necessary to get this measurement up and running. We’ve got methods for simulated cold startup from Vlad, Rob Arnold and others. Next steps: Implement support for head/tail scripts for Talos tests, write those scripts for cold startup for all platforms, hand off to rel-eng for deployment.
- Joel Reymont started working on Firefox performance on Mac, and posted a comparison of dynamic linking time for Firefox and Safari, and started posting notes on his methodology on the wiki.
- Vlad landed bug 506470, which delays the initialization of Growl on Mac, winning 7.5% on Ts. As seen above, it’s a win on dirty profiles without Growl as well as regular Ts (empty profile).
- Taras Glek posted a summary of ways to spend less time in disk IO at startup, the performance characteristics of IO on restricted devices, and a log of files opened at startup.
Further Reading
[UPDATE: Added Taras' post, and a link to Joel's notes.]






August 22, 2009 12:16 AM
August 21, 2009
The mozilla-1.9.2 branch (aka the Firefox 3.6 branch) went live last week, quietly and with no fuss. My last post is now out of date. The newly increased list of active branches is:
- Firefox 3.0.x (aka cvs-trunk, mozilla-1.9.0)
- Firefox 3.5.x (aka mozilla-1.9.1)
- Firefox 3.6.x (aka mozilla-1.9.2)
- Firefox 3.next (aka mozilla-central)
- mobile-browser
- TraceMonkey
- Places
- Electrolysis
- Thunderbird 2.0.0.x (aka mozilla-1.8.1)
What struck me the most about setting up this mozilla-1.9.2 branch was how smoothly it went. Even with the other distractions and complications going on at the time, setting up this new mozilla-1.9.2 branch felt to me like the smoothest new branch setup I’d seen so far. An encouraging metric for how our infrastructure is scaling up.
Nice, very nice.
Updated: Aki pointed out that I’d forgotten to include the mobile-browser codeline.  Now added. joduinn 24aug2009
Now added. joduinn 24aug2009
August 21, 2009 11:48 PM

















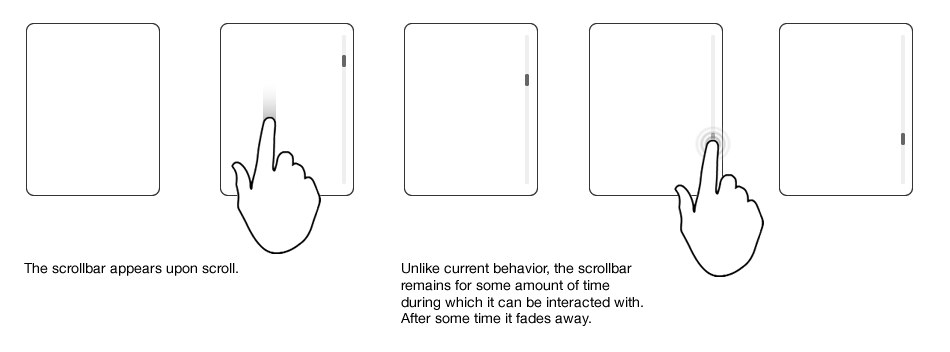
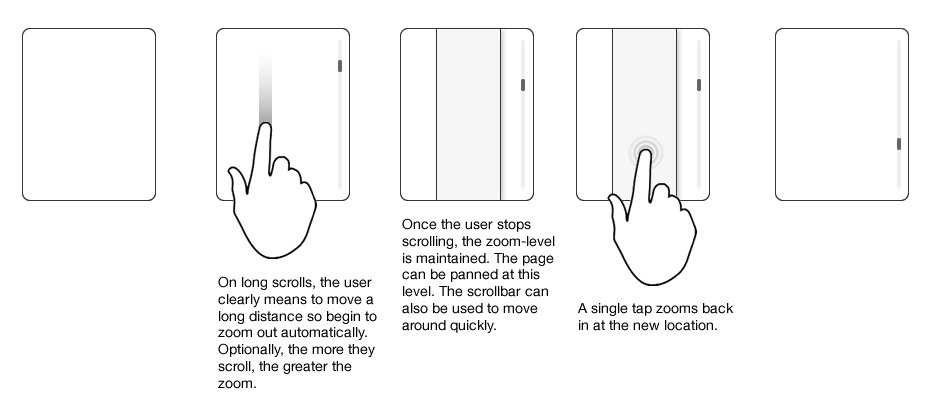

![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=06f40e5a-2a24-45f3-bb24-7183d1f17bdd)
{kind=link}